![[Photo of the Author]](../../common/images/Ismael-R.gif) Ismael Ripoll Sobre el Autor: Doctorado por la Universidad Politécnica de Valencia in 1996. Profesor en Sistemas Operativos en el Departamento DISCA. Investigando en temas de tiempo-real y sistemas operativos. Usuario de Linux desde 1994. Hobbies: Treking en los Pirineos, esquiar y electrónica casera. Índice de contenidos: KU Real Time Linux (KURT) ¿Para qué sirve el Tiempo Real? Módulos cargables El programa de Tiempo Real Comunicación entre tareas Conclusión Bibliografía |
Real Time Linux II![[Ilustration]](../../common/images/illustration33.gif)
Resumen: En este segundo artículo dedicado a RT-Linux, trataré de ofrecer una visión más práctica de RT-Linux. Antes de entrar en detalle me gustaría dar una rápida visión general de un nuevo sistema operativo de tiempo real sobre Linux KURT. KU Real Time Linux (KURT)A principios de este mismo año (1998) se presento un nuevo sistema operativo de tiempo real basado en Linux. KURT es un sistema de tiempo real blando (soft, or firm), esto es, se intentan cumplir los plazos de ejecución, pero en caso que alguna tarea finalice un poco tarde no sucede ningún desastre. Las tareas de tiempo real de KURT pueden hacer uso de todas las facilidades Linux, al contrario que las tareas de RT-Linux. Las mejoras --modificaciones-- se han realizado sobre el núcleo son:
Las tareas de tiempo real son módulos de carga dinámica. Uno de los aspectos más característicos de KURT es la política de planificación que utiliza. Se ha implementado un planificador cíclico. Éste tipo de planificadores se basa en el uso de una tabla (llamada plan) en la que están anotadas todas las acciones de planificación: instante de activación, tarea a ejecutar, duración de éstas, etc.. La tabla se construye durante la fase de diseño del sistema y luego durante la ejecución, el trabajo del planificador consiste en leer secuencialmente la tabla y seguir sus indicaciones. Cuando se llega al final de la tabla, se vuelve a repetir la ejecución desde el principio de la tabla, de ahí el nombre de la política de planificación. Este método de planificación tiene muchas ventajas:
El principal inconveniente radica en la dificultad de construir el plan. Y cada vez que se altera alguno de los parámetros de las tareas hay que reconstruir el plan completo. Por otra parte, el tamaño del plan, y por tanto la cantidad de memoria necesaria para almacenarlo, suele ser muy grande. ¿Para qué sirve el Tiempo Real?Quizás muchos crean que las técnicas de tiempo real sólo se utilizan en la nasa, o en misiles o cosas por el estilo. Si bien esto podía ser cierto hace unos años, hoy en día la situación ha cambiado mucho --y aún ha de cambiar más-- debido a la progresiva incorporación de la informática y la electrónica en la vida cotidiana. El ámbito de la vida cotidiana en el que más está presente el Tiempo-Real es el campo de las telecomunicaciones y las aplicaciones multimedia. Por ejemplo, si queremos que nuestro ordenador sea capaz de reproducir un fichero de sonido que tenemos grabado en el disco, el programa tendrá que continuamente (mejor dicho, periódicamente) leer, descomprimir y enviar a la tarjeta de sonido los sonidos. Si a la vez que estamos escuchando la grabación, estamos trabajando con un programa como un editor de textos o sencillamente estamos compilando el núcleo de Linux, es seguro que se producirán silencios debido a que el procesador está ocupado haciendo otras tareas. Si en lugar de sonido, lo que estamos reproduciendo es vídeo, entonces se producirán saltos o cortes en la imagen. Este tipo de sistemas se denominan sistemas de tiempo real blando (el incumplimiento de un plazo de ejecución no produce un desastre grave, pero sí una degradación de las prestaciones). Las aplicaciones de RT-Linux van más allá de las aplicaciones estrictamente de tiempo real. Con RT-Linux podemos tomar el control total del PC (digo PC y no ordenador porque por ahora todavía no hay ninguna implementación de RT-Linux para otra arquitectura) tal como se puede hacer en MSDOS. En una tarea de tiempo real podemos acceder a todos los puertos del PC, instalar manejadores de interrupciones, inhabilitar temporalmente las interrupciones... o sea que podemos dejar "colgada" la máquina como si de un Windows se tratara. Esta posibilidad es muy atractiva para todos aquellos que nos gusta conectar pequeños "gadgets" electrónicos al ordenador. Módulos cargablesPara entender y poder utilizar RT-Linux es necesario conocer los módulos de carga dinámicos de Linux. Matt Welsh ha escrito un completo artículo en el que explica en profundidad todos los aspectos de los módulos. ¿Qué son?En la mayoría de las implementaciones de UNIX, la única forma de acceder al hardware (puertos, memoria, interrupciones, etc.) es mediante los ficheros especiales, teniendo previamente instalado el manejador del dispositivo (device drier). A pesar de que existen muy buenos libros que explican cómo construir manejadores de dispositivos, suele ser una labor larga y aburrida, pues hay que implementar muchas funciones para poder enlazarlo con el sistema operativo. Los módulos son "trozos de sistema operativo" que se pueden insertar y extraer en tiempo de ejecución. Cuando se compila un programa compuesto por varios ficheros fuente, primero se compilan por separado cada fichero para producir el fichero objeto, ".o", y luego se enlazan todos juntos, resolviendo todas las referencias, para crear un único ejecutable. Supongamos que el fichero objeto que contiene la función main pudiéramos ponerlo en ejecución, y que el sistema operativo fuera capaz de cargar en memoria y enlazar el resto de los ficheros sólo cuando fueran necesarios. Bien, pues el núcleo de Linux es capaz de hacer ésto con el propio núcleo. Cuando Linux arranca sólo se carga en memoria el ejecutable vmlinuz, que contiene las partes indispensables, y luego en tiempo de ejecución se puede cargar y descargar selectivamente los módulos que se necesiten en cada momento. Los módulos son una característica opcional de Linux que se elige cuando se compila el núcleo. Los núcleos de todas las distribuciones que conozco han sido compilados con la opción de módulos activada. Podemos incluso crear nuevos módulos y cargarlos sin necesidad de recompilar ni rearrancar el ordenador. Una vez cargado un módulo, pasa a formar parte del propio sistema operativo, por lo que:
Como podemos ver, un módulo de carga dinámica en sí mismo ya tienen unas cuantas características de tiempo real: evita los retrasos por fallos de página y tiene acceso a todos los recursos del hardware. ¿Cómo se crean y utilizan?Un módulo se crea a partir de un fuente en "C". A continuación tenemos un módulo mínimo (para poder hacer la mayoría de las siguientes ordenes es necesario ser super-usuario, root) : ejemplo1.c #define MODULE
#include <linux/module.h>
#include <linux/cons.h>
static int output=1;
int init_module(void) {
printk("Output= %d\n",output);
return 0;
}
void cleanup_module(void){
printk("Adiós, By, Chao, Ovuar, \n");
}
Para compilarlo utilizaremos los siguientes parámetros: # gcc -I /usr/src/linux/include/linux -O2 -Wall -D__KERNEL__ -c ejemplo1.c La opción -c le indica al gcc debe detenerse una vez haya obtenido el fichero objeto, eliminando la fase de enlazado (link). El resultado es el fichero objeto ejemplo1.o.El núcleo no dispone de salida estándar, por lo que no podemos utilizar la función printf()... a cambio, el núcleo ofrece una versión de ésta llamada printk(), que funciona casi igual sólo que el resultado lo imprime sobre un buffer circular de mensajes (kernel ring buffer). En este buffer es donde se escriben todos los mensajes del núcleo, de echo, son los mensajes que vemos cuando arranca Linux. En cualquier momento podemos ver el contenido con la orden dmesg o directamente consultado el fichero /proc/kmsg. Como podemos ver, no está la función main() en su lugar se llama a la función init_module() a la que no se le pasa ningún parámetro. Antes de descargar el módulo se llama cleanup_module(). Para cargar el módulo se hace con la orden insmod. # insmod ejemplo1.o Acabamos de instalar ejemplo1 y ejecutar su función init_module(). Si queremos ver los resultados llamamos: # dmesg | tail -1 Output= 1 La orden lsmod permite listar los módulos que en un momento dado tenemos instalados: # lsmod Module Pages Used by: ejemplo1 1 0 sb 6 1 uart401 2 [sb] 1 sound 16 [sb uart401] 0 (autoclean) Y finalmente con rmmod descargamos un módulo: # rmmod ejemplo1 # dmesg | tail -2 Output= 1 Adiós, By, Chao, Orvua, La salida de dmesg nos muestra que se ha ejecutado la función cleanup_module(). Sólo nos queda por saber cómo se pueden pasar parámetros a un módulo. No hay nada más sencillo y sorprendente. Podemos asignar valores a las variables globales con sólo escribir la asignación como parámetro de insmod. Por ejemplo: # insmod ejemplo1.o output=4< # dmesg | tail -3 Output= 1 Adíos, By, Chao, Orvua, Output= 4 Ahora ya sabemos todo lo necesario sobre módulos, volvamos a RT-Linux. El primer programa de Tiempo RealRecordemos que para poder utilizar RT-Linux, primero hemos tenido que preparar el núcleo de Linux para soportar los módulos de tiempo real, operación que se explicó en el primer número de la serie. Podemos utilizar RT-Linux de dos formas distintas:
En este artículo sólo explicaré cómo utilizar RT-Linux como un sistema con prioridades fijas. El ejemplo que vamos a ver no hace nada "útil", tan sólo pone en marcha una tarea de tiempo real, que es un simple bucle: ejemplo2.c #define MODULE
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/version.h>
#include <linux/rt_sched.h>
RT_TASK task;
void fun(int computo) {
int bucle,x,limite;
limite = 10;
while(1){
for (bucle=0; bucle<computo; bucle++)
for (x=1; x<limite; x++);
rt_task_wait();
}
}
int init_module(void) {
RTIME now = rt_get_time();
rt_task_init(&task,fun, 50 , 3000, 1);
rt_task_make_periodic(&task,
now+(RTIME)(RT_TICKS_PER_SEC*4000)/1000000,
(RTIME)(RT_TICKS_PER_SEC * 100)/1000000);
return 0;
}
void cleanup_module(void){
rt_task_delete(&task);
}Para compilarlo utilizaremos la siguiente línea de orden: # gcc -I /usr/src/linux/include/linux -O2 -Wall -D__KERNEL__ -D__RT__ -c ejemplo2.cPuesto que este programa es un módulo, el punto de entrada es la función init_module(). Lo primero que hace es leer el instante de tiempo actual y lo guarda en una variable local; la función rt_get_time() devuelve el número de RT_TICKS_PER_SEC transcurridos desde que se arrancó el ordenador (que en la actual implementación RT_TICKS_PER_SEC vale 1.193.180, lo que da una resolución de 0.838 micro-segundos). Con rt_task_init() se inicializa la estructura task pero no se pone en marcha la tarea. El programa principal de la recién creada tarea es fun(), el segundo parámetro. El siguiente parámetro es el valor del dato que se le pasará a la nueva tarea cuando comience su ejecución, observa que fun() espera un parámetro de tipo int. El siguiente parámetro es el tamaño de la pila de la tarea; puesto que cada tarea tiene un hilo de ejecución propio, necesita una pila propia. El último parámetro es la prioridad; en este caso, con una sola tarea en el sistema, se puede poner cualquier valor de prioridad. rt_task_make_periodic() convierte a la tarea task en una tarea periódica. El primer tiempo es el instante de tiempo absoluto en el que se activará por primera vez y el siguiente parámetro indica el periodo entre activaciones sucesivas a partir de la primera. La tarea de tiempo real (función fun()), es un bucle infinito, dentro del cual sólo hay dos acciones: un bucle que sólo sirve para gastar tiempo, y luego llama a rt_task_wait(). rt_task_wait(), es una función que suspende la ejecución de la tarea que la invoca hasta la siguiente activación, momento en el que continuará la ejecución con la siguiente instrucción después de rt_task_wait(). Observa que una tarea periódica no se ejecuta desde el principio en cada activación, sino que la propia tarea ha de suspenderse (cuando ha finalizado su trabajo) y esperar a la siguiente activación. De está forma podemos programar una tarea para que solo en la primera activación realice ciertas labores de inicialización. Para poder poner ejemplo2 en ejecución se ha de instalar primero el módulo rt_prio_sched, pues necesitamos las funciones rt_task_make_periodic(), rt_task_delete() y rt_task_init(). La función rt_get_time() no está dentro de ningún módulo, sino que está compilada dentro del núcleo, y por tanto no hay que instalar nada para poder utilizarla. # modprobe rt_prio_sched # insmod ./ejemplo2.oPuesto que rt_prio_sched es un módulo del sistema, lo hemos creado cuando compilamos el núcleo de Linux y se ha copiado al directorio /var/modules/2.0.33/, podemos utilizar la orden modprobe, que es simplemente una forma más fácil de cagar módulos (es capaz de buscar el módulo pedido en varios directorios. Ver modprobe(1)). Si todo ha ido bien, con la orden lsmod podemos ver que los dos módulos se han cargado correctamente. Bueno, pues ya tenemos una tarea de tiempo real en marcha ¿Notas algo? Si el procesador es un poco lento, posiblemente notes que Linux va un poco más despacio de lo normal. Puedes aumentar el número de iteraciones del bucle de fun(), variando el tercer parámetro de rt_task_init(). Una forma de apreciar que Linux tiene menos tiempo de procesador es con el programa ico, pues el tiempo empleado por las tareas de tiempo real es, a todos los efectos, como si el procesador funcionara más despacio; Linux cree que todos sus procesos necesitan más tiempo para hacer lo mismo. Si el tiempo de cómputo (tiempo necesario para ejecutar todas las iteraciones del bucle) de la tarea es superior a 100 microsegundos entonces Linux se "colgará", pues es la tarea en background, y la tarea de tiempo real consume el 100% del tiempo. Realmente, Linux NO se ha colgado, sencillamente no tiene tiempo de procesador. Comunicación entre tareasEn RT-Linux sólo hay una forma de comunicación: Real-Time FIFO. El funcionamiento es muy similar a las tuberías (PIPE's) de Unix, la comunicación es por flujo de datos sin estructura. Una FIFO es un buffer de bytes de tamaño fijo sobre el que se pueden hacer operaciones de lectura y escritura. Con las FIFOS podemos comunicar tanto tareas de tiempo real entre sí, como tareas de tiempo real con procesos Linux normales. Desde el punto de vista de un proceso Linux normal una FIFO es un fichero especial de caracteres. Normalmente estará en /dev/rtf0, /dev/rtf1, etc. Estos fichero no existen en Linux por lo que hay que crearlos. Lo podemos hacer de la siguiente forma: # for i in 0 1 2 3; do mknod /dev/rtf$i c 63 $i; done Si necesitamos más FIFOs sólo hay que crearlas rtf4, rtf5 etc. Los ficheros especiales son el interfaz de acceso a un manejador del sistema operativo, pero si el manejador no existe entonces no sirve de nada el fichero especial, de hecho, intentar abrir un fichero especial del cual el sistema operativo no tiene el manejador asociado fallará.
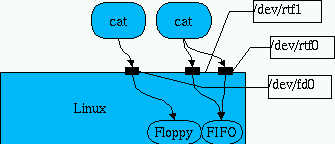
Las FIFOS se utilizan como si fueran ficheros normales (open read/write close). Para poder utilizarlas han de existir, esto es, una tarea de tiempo real ha de haber creado la FIFO antes de que un proceso normal de Linux pueda hacer un open sobre ella. Desde el punto de vista de una tarea de tiempo real, las FIFOS se utilizan mediante funciones específicas:
Veamos ahora un ejemplo de sistema que hace uso de estas funciones. Este ejemplo es una pequeña modificación de uno de los ejemplos que hay en la distribución de RT-Linux (sound): ejemplo3.c #define MODULE
#include <linux/module.h>
#include <linux/rt_sched.h>
#include <linux/rtf.h>
#include <asm/io.h>
RT_TASK task;
static int filter(int x){
static int oldx;
int ret;
if (x & 0x80) {
x = 382 - x;
}
ret = x > oldx;
oldx = x;
return ret;
}
void fun(int dummy) {
char data;
char temp;
while (1) {
if (rtf_get(0, &data, 1) > 0) {
data = filter(data);
temp = inb(0x61);
temp &= 0xfd;
temp |= (data & 1) <<
1;
outb(temp,0x61);
}
rt_task_wait();
}
}
int init_module(void){
rtf_create(0, 4000);
/* enable counter 2 */
outb_p(inb_p(0x61)|3, 0x61);
/* to ensure that the output of the counter is 1 */
outb_p(0xb0, 0x43);
outb_p(3, 0x42);
outb_p(00, 0x42);
rt_task_init(&task, fun, 0 , 3000, 1);
rt_task_make_periodic(&task,
(RTIME)rt_get_time()+(RTIME)1000LL,
(RTIME)(RT_TICKS_PER_SEC / 8192LL));
return 0;
}
void cleanup_module(void){
rt_task_delete(&task);
rtf_destroy(0);
}Al igual que en el ejemplo2, necesitamos los servicios del módulo rt_prio_sched, pero ahora también necesitamos los servicios del módulo rt_fifo_new para poder utilizar las FIFO's. Se crea una tarea de tiempo real periódica con una frecuencia de 8192Hz. Esta tarea lee bytes de la FIFO cero, y si encuentra algo lo envía al puerto del altavoz del PC. Si copiamos un fichero de sonido en formato ".au" sobre /dev/rtf0, podremos oírlo. No es necesario decir que la calidad de sonido es pésima pues el hardware del PC solo permite utilizar un bit para modular señal. En el directorio testing/sound de la distribución podemos encontrar el fichero linux.au para hacer pruebas. Para compilarlo y ejecutarlo: # gcc -I /usr/src/linux/include/linux -O2 -Wall -D__KERNEL__ -D__RT__ -c ejemplo3.c# modprobe rt_fifo_new # modprobe rt_prio_sched # insmod ejemplo3.o # cat linux.au > /dev/rtf0 Observa como el programa cat se puede utilizar para escribir sobre cualquier fichero, incluidos los ficheros especiales. También podríamos utilizar la orden cp. Para poder ver cómo afecta el tiempo real a la calidad de reproducción, sólo tenemos que escribir un programa que haga lo mismo pero desde un proceso de usuario: ejemplo4.c #include <unistd.h>
#include <asm/io.h>
#include <time.h>
static int filter(int x){
static int oldx;
int ret;
if (x & 0x80)
x = 382 - x;
ret = x > oldx;
oldx = x;
return ret;
}
espera(int x){
int v;
for (v=0; v<x; v++);
}
void fun() {
char data;
char temp;
while (1) {
if (read(0, &data, 1) > 0) {
data = filter(data);
temp = inb(0x61);
temp &= 0xfd;
temp |= (data & 1) << 1;
outb(temp,0x61);
}
espera(3000);
}
}
int main(void){
unsigned char dummy,x;
ioperm(0x42, 0x3,1); ioperm(0x61, 0x1,1);
dummy= inb(0x61);espera(10);
outb(dummy|3, 0x61);
outb(0xb0, 0x43);espera(10);
outb(3, 0x42);espera(10);
outb(00, 0x42);
fun();
}Este programa se compila como un programa normal: # gcc -O2 ejemplo4.c -o ejemplo4 Y para ejecutarlo: # cat linux.au | ejemplo4 Para poder acceder a los puertos hardware del ordenados desde un programa normal de Linux hay que pedir permiso al sistema operativo. Esto es una medida de protección básica y necesaria para evitar que un programa pueda acceder por ejemplo al disco duro directamente. La llamada ioperm() sirve para indicar al sistema operativo que queremos acceder a un determinado rango de direcciones de entrada/salida. Sólo se les concederá el acceso a los programas que se ejecuten con permisos de super-usuario. Otro detalle a destacar es cómo se genera la frecuencia de 8192Hz ala que se emite el sonido. Si bien existe la llamada nanodelay(), ésta sólo tiene una resolución del orden del milisegundo, por lo que tenemos que hacer uso de la temporización por bucle de espera. El bucle está ajustado para que más o menos funcione sobre un Pentium 100Mhz. Ahora prueba a ejecutar ejemplo4 junto con el programa ico ¿Qué tal se oye? ¿Te parece ahora que el tiempo real sirve para algo? ConclusiónEste segundo artículo ha estado centrado en los detalles de programación de tareas de tiempo real. Los ejemplos presentados son bastante simples y carentes de utilidad, en el siguiente número presentare una aplicación más útil. Podremos controlar la televisión desde Linux o todavía más sorprendente, controlar tu Linux desde el mando a distancia!! |
Texto original en Castellano
|
Páginas web Mantenidas por Miguel Angel Sepulveda © Ismael Ripoll 1998 LinuxFocus 1998 |