![[Photo de l'auteur]](../../common/images/Ismael-R.gif) Ismael Ripoll À propos de l'auteur : Docteur de l'université polytechnique de Valence (Espagne) en 1996. Professeur en systèmes d'exploitation au département de DISCA. Sujets de recherche : ordonnancement temps réel et systèmes d'exploitation. Utilisateur de GNU/Linux depuis 1994. Loisirs : randonnée dans les Pyrénées, ski, électronique.
Traduit en français par
Sébastien Blondeel.
|
Linux temps réel II![[Illustration]](../../common/images/illustration33.gif)
Résumé : Dans ce deuxième numéro dédié à RT-Linux je tenterai de proposer une vue plus pratique de RT-Linux. Avant de rentrer dans les détails, toutefois, je donnerai un aperçu rapide d'un système d'exploitation temps réel très récent, appelé Linux KURT. KU Real Time Linux (KURT)Au début de cette année (1998), on a vu sortir un nouveau système d'exploitation temps réel fondé sur GNU/Linux. KURT est un système d'exploitation temps réel souple (et non pas ferme), c.à.d. que l'ordonnanceur tente de satisfaire les temps d'exécution réclamés, mais si une tâche prend du retard ce n'est pas vraiment une tragédie et rien de dramatique ne se produit. Les tâches temps réel de KURT peuvent profiter de toutes les fonctionnalités de GNU/Linux, au contraire des tâches de RT-Linux. Les améliorations --- modifications --- apportées au noyau sont :
Les tâches temps réel sont des modules chargés dynamiquement. Une des fonctionnalités les plus caractérisques de KURT est sa politique d'ordonnancement. Il a été décidé d'implanter un ordonnanceur cyclique. Ce type d'ordonnanceurs utilise une table appelée plan qui contient les actions ordonnancées : moment de l'activation, tâche à exécuter, durée de la tâche, etc. Cette table est construite pendant la phase de mise au point du système. Plus tard, pendant l'exécution, le travail de l'ordonnanceur consiste simplement à lire séquentiellement la table en suivant ses instructions. Quand on atteint la fin de la table, l'ordonnanceur retourne au début et continue à exécuter les tâches --- d'où le nom d'ordonnanceur cyclique. Ce type d'ordonnanceur présente de nombreux avantages :
La difficulté principale réside à générer le plan lui-même. De plus, dès qu'un des paramètres des tâches est modifié, il est nécessaire de reconstruire le plan, et il faut souvent beaucoup de mémoire pour le stocker. À quoi sert le temps réel ?Nombreux sont ceux qui pensent peut-être que les techniques temps réel ne sont utilisées que par la NASA (Agence spatiale d'Amérique du Nord), ou avec des missiles ou des artefacts semblables. Cela était vrai il y a quelques années, mais de nos jours la situation a bien changé --- et ce n'est pas fini --- à cause de l'intégration de systèmes d'information et d'électronique dans la vie de tous les jours des gens. On trouve par exemple le temps réel dans les télécommunications et les applications multimedia. Par exemple, si on souhaite que l'ordinateur joue un fichier son stocké sur le disque dur, un programme devrait continûment (ou mieux, périodiquement) lire, décompresser et envoyer les données sonores à la carte son. Si en même temps qu'en écoute la musique, on travaille avec une application, comme un traitement de texte ou la simple compilation du noyau lui-même, il est certain que des blancs se feront entendre périodiquement, pendant que le noyau gérera d'autres tâches. Si au lieu de produire du son, on produisait de la vidéo sur notre système, on obtiendrait une diffusion avec des arrêts sur image intermittents. On appelle ce genre de systèmes temps réel souple (le viol d'une période d'exécution ne produit pas un résultat désastreux, mais il dégrade les services proposés par le système). Les applications de RT-Linux vont plus loin que les applications temps réel normales. Grâce à RT-Linux, on peut prendre le contrôle total du PC (je dis PC et non par ordinateur car pour le moment on ne trouve RT-Linux que pour cette architecture), comme c'est le cas avec MS-DOS. Pendant une tâche temps réel il est possible d'accéder à tous les ports du PC, installer des gestionnaires d'interruptions, désactiver temporairement les interruptions, ... en d'autres termes, on peut « écrouler » le système comme s'il s'agissait d'un système MS-Windows. Cette opportunité est toutefois très attrayante à ceux d'entre nous qui aiment attacher de petits « gadgets » électroniques à l'ordinateur. Modules chargeablesPour comprendre RT-Linux et pouvoir l'utiliser, il faut connaître les modules de Linux qu'on peut charger dynamiquement. Matt Welsh a rédigé un article complet où il explique en détail tout ce qui concerne les modules. Qu'est-ce que c'est ?Dans la plupart des implantations d'Unix, la seule manière d'accéder au matériel (les ports, la mémoire, les interruptions, etc.) et de passer par des fichiers particuliers et d'avoir installé au préalable les pilotes de périphériques. Même si les livres de qualité expliquant comment écrire des pilotes de périphériques ne manquent pas, c'est souvent un travail long et ennuyeux, puisqu'il est nécessaire d'écrire de nombreuses fonctions pour lier le pilote au système. Les modules sont des «fragments du système
d'exploitation»
qu'on peut insérer et extraire au moment de l'exécution. Quand
on compile un programme comprenant plusieurs fichiers source, chaque
fichier est compilé séparément, dans un premier temps, pour engendrer un
fichier objet «.o»,
puis les objets sont liés ensemble, en résolvant toutes les références
et en engendrant un fichier exécutable unique.
Supposons que le fichier objet comportant la fonction
Les modules forment une fonctionnalité optionnelle du noyau Linux, qu'il faut préciser au moment de la compilation du noyau. Les noyaux de toutes les distributions que je connais ont été compilés avec cette option activée. Il est même possible de créer de nouveaux modules et de les charger sans devoir recompiler ou réamorcer le système Quand un module est chargé, il se transforme en partie intégrante du système d'exploitation donc :
Comme on peut le voir, un module chargé dynamiquement dispose déjà de certaines des caractérisques d'un programme temps réel : il évite les retards provoqués par des fautes de pages et il peut accéder à toutes les ressources du matériel. Comment les construire et les utiliser ?
Un module est construit à partir d'un code source écrit en langage
«C». Voici un exemple de module minuscule (pour exécuter la
plupart des commandes suivantes il faut être super utilisateur ou
#define MODULE
#include <linux/module.h>
#include <linux/cons.h>
static int output=1;
int init_module(void) {
printk("Output= %d\n",output);
return 0;
}
void cleanup_module(void){
printk("Adiós, Bye, Ciao, Ovuar, \n");
}
Pour le compiler on utilise les paramètres suivants :
# gcc -I /usr/src/linux/include/linux -O2 -Wall -D__KERNEL__ -c exemple1.c
Le commutateur
Le noyau ne dispose pas de sortie standard, aussi ne pouvons-nous pas
utiliser la fonction
Remarquez l'absence de la fonction # insmod exemple1.o
On a maintenant installé le module # dmesg | tail -1 Output= 1
La commande # lsmod Module Pages Used by: exemple1 1 0 sb 6 1 uart401 2 [sb] 1 sound 16 [sb uart401] 0 (autoclean)
Enfin, on utilise la commande
# rmmod exemple1 # dmesg | tail -2 Output= 1 Adiós, Bye, Ciao, Orvua,
La sortie de la commande
Il ne nous reste plus qu'à savoir comment passer des paramètres à un
module. De façon surprenante, rien n'est plus simple. On peut affecter
des valeurs aux variables globales en passant des paramètres à la
fonction # insmod exemple1.o output=4 # dmesg | tail -3 Output= 1 Adíos, Bye, Chao, Ovuar, Output= 4 Maitenant qu'on sait tout ce qu'il faut savoir sur les modules, revenons à RT-Linux. Notre premier programme temps réelIl faut d'abord se rappeler que pour utiliser RT-Linux, il faut d'abord préparer le noyau Linux à proposer une assistance pour les modules temps réel — on a parlé de cette opération dans l'article précédent. Il y a deux manières d'utiliser RT-Linux :
Cette fois-ci, je discuterai de la manière d'utiliser RT-Linux en tant que système disposant de priorités fixes. L'exemple que nous allons voir ne fait rien d'"utile", il se permet de mettre en place une tâche temps réel (une simple boucle) : exemple2.c
#define MODULE
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/version.h>
#include <linux/rt_sched.h>
RT_TASK task;
void fun(int je_calcule) {
int boucle,x,limite;
limite = 10;
while(1){
for (boucle=0; boucle<je_calcule; boucle++)
for (x=1; x<limite; x++);
rt_task_wait();
}
}
int init_module(void) {
RTIME now = rt_get_time();
rt_task_init(&task,fun, 50 , 3000, 1);
rt_task_make_periodic(&task,
now+(RTIME)(RT_TICKS_PER_SEC*4000)/1000000,
(RTIME)(RT_TICKS_PER_SEC * 100)/1000000);
return 0;
}
void cleanup_module(void){
rt_task_delete(&task);
}Une fois encore, on compile cet exemple en utilisant la commande suivante :
# gcc -I /usr/src/linux/include/linux -O2 -Wall -D__KERNEL__ -D__RT__ -c
exemple2.c
Puisque ce programme est un module, le point d'entrée est la fonction
La fonction
La tâche temps réel (la fonction
Pour exécuter le programme # modprobe rt_prio_sched # insmod ./exemple2.o
Étant donné que le module
Si tout s'est bien passé, la commande
Bien, à ce point ci le lecteur dispose déjà d'un programme temps réel en
cours d'exécution. Remarquez-vous quoi que ce soit ?
Si le processeur est un peu lent, le lecteur remarquera probablement que
Linux fonctionne un peu moins vite que d'habitude. Vous pouvez tenter
d'incrémenter le nombre d'itérations à l'intérieur de la boucle
de Communication entre les tâchesSous le système RT-Linux, il n'existe qu'un seul moyen de communication : les files de type FIFO temps réel. Leur mode de fonctionnement est très semblable à celui des tuyaux (pipe) sous Unix, une communication par flot de données sans structure. Une file FIFO est un tampon d'un nombre d'octets fixé sur lequel on peut effectuer des opérations de lecture et d'écriture. En utilisant des files de type FIFO, il est possible d'établir des communications entre tâches temps réel aussi bien qu'entre des tâches normales sous Linux.
Du point de vue d'un processus normal, une file de type
FIFO est un fichier à caractère particulier. On les trouve
habituellement sous les noms
# for i in 0 1 2 3; do mknod /dev/rtf$i c 63 $i; done
S'il vous faut plus de files de type FIFO, vous pouvez facilement les
créer en utilisant la même procédure pour les fichiers
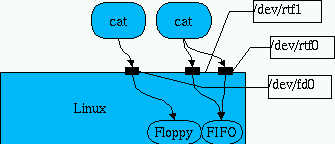
On utilise les files de type FIFO comme si elles étaient des fichiers
normaux (avec les fonctions
Du point de vue d'une tâche temps réel, les files de type FIFO sont utilisées à travers des fonctions spécifiques :
Considérons maintenant un exemple de système qui utilise ces fonctions. Cet exemple est une petite modification d'un des exemples dans la distribution de RT-Linux (sound) : exemple3.c
#define MODULE
#include <linux/module.h>
#include <linux/rt_sched.h>
#include <linux/rtf.h>
#include <asm/io.h>
RT_TASK tache;
static int filter(int x){
static int vieil_x;
int ret;
if (x & 0x80) {
x = 382 - x;
}
ret = x > vieil_x;
vieil_x = x;
return ret;
}
void fun(int mannequin) {
char donnees;
char temp;
while (1) {
if (rtf_get(0, &donnees, 1) > 0) {
donnees = filter(donnees);
temp = inb(0x61);
temp &= 0xfd;
temp |= (donnees & 1) << 1;
outb(temp,0x61);
}
rt_task_wait();
}
}
int init_module(void){
rtf_create(0, 4000);
/* met en place le compteur numéro 2 */
outb_p(inb_p(0x61)|3, 0x61);
/* pour s'assurer que le compteur renvoie 1 */
outb_p(0xb0, 0x43);
outb_p(3, 0x42);
outb_p(00, 0x42);
rt_task_init(&tache, fun, 0 , 3000, 1);
rt_task_make_periodic(&tache,
(RTIME)rt_get_time()+(RTIME)1000LL,
(RTIME)(RT_TICKS_PER_SEC / 8192LL));
return 0;
}
void cleanup_module(void){
rt_task_delete(&tache);
rtf_destroy(0);
}
Comme dans le deuxième exemple, on a besoin des services du module
Une tâche temps réel périodique de fréquence 8192 Hz est créée.
Cette tâche lit des octets dans la file de type FIFO numéro 0, et
si elle trouve quelque chose elle l'envoie au port du haut-parleur de
l'ordinateur personnel de type PC. Si on copie un fichier son au format
".au" sur la file Pour le compiler et l'exécuter :
# gcc -I /usr/src/linux/include/linux -O2 -Wall -D__KERNEL__ -D__RT__ -c exemple3.c
Remarquez de quelle manière on peut utiliser l'outil Pour comparer la manière dont les fonctionnalités du temps réel affectent la qualité de la reproduction, il nous suffit d'écrire un programme qui fasse la même opération, mais à partir d'un processus utilisateur normal de Linux : exemple4.c
#include <unistd.h>
#include <asm/io.h>
#include <time.h>
static int filter(int x){
static int vieil_x;
int ret;
if (x & 0x80)
x = 382 - x;
ret = x > vieil_x;
vieil_x = x;
return ret;
}
attends(int x){
int v;
for (v=0; v<x; v++);
}
void fun() {
char donnees;
char temp;
while (1) {
if (read(0, &donnees, 1) > 0) {
donnees = filter(donnees);
temp = inb(0x61);
temp &= 0xfd;
temp |= (donnees & 1) << 1;
outb(temp,0x61);
}
attends(3000);
}
}
int main(void){
unsigned char mannequin,x;
ioperm(0x42, 0x3,1); ioperm(0x61, 0x1,1);
mannequin= inb(0x61);attends(10);
outb(mannequin|3, 0x61);
outb(0xb0, 0x43);attends(10);
outb(3, 0x42);attends(10);
outb(00, 0x42);
fun();
}On peut compiler ce programme comme tout programme normal : # gcc -O2 exemple4.c -o exemple4 Et pour l'exécuter : # cat linux.au | exemple4
Pour accéder aux ports matériels de l'ordinateur à partir d'un
programme normal de Linux il faut l'autorisation du système
d'exploitation. C'est une mesure de protection élémentaire et nécessaire
pour éviter de programmer des accès directs au disque dur, par exemple.
L'appel
Je suggère maintenant au lecteur de tester
l' ConclusionCe deuxième article a mis l'accent sur les détails de programmation des tâches temps réel. Les exemples présentés sont très simples et manquent d'utilisation pratique, mais dans l'article suivant je proposerai une application plus utile. Nous serons capables de contrôler le téléviseur à partir de GNU/Linux ou, plus surprenant encore, de contrôler une linuxette grâce à une télécommande ! . |
Traduit en français par Sébastien Blondeel.
|
© Ismael Ripoll 1998 LinuxFocus 1998 Contacter le Webmestre. |