
![]()
![]()
torchaudio is an extension for torch providing
audio loading, transformations, common architectures for signal
processing, pre-trained weights and access to commonly used datasets.
The package is a port to R of PyTorch’s
TorchAudio.
torchaudio was originally developed by Athos Damiani as part of Curso-R work. Development will
continue under the roof of the mlverse organization, together
with torch itself, torchvision,
luz, and a
number of extensions building on torch.
The CRAN release can be installed with:
install.packages("torchaudio")You can install the development version from GitHub with:
remotes::install_github("mlverse/torchaudio")torchaudio supports a variety of workflows – such as
training a neural network on a speech dataset, say – but to get started,
let’s do something more basic: load a sound file, extract some
information about it, convert it to something torchaudio
can work with (a tensor), and display a spectrogram.
Here is an example sound:
library(torchaudio)
url <- "https://pytorch.org/tutorials/_static/img/steam-train-whistle-daniel_simon-converted-from-mp3.wav"
soundfile <- tempfile(fileext = ".wav")
r <- httr::GET(url, httr::write_disk(soundfile, overwrite = TRUE))Using torchaudio_info(), we obtain number of channels,
number of samples, and the sampling rate:
info <- torchaudio_info(soundfile)
cat("Number of channels: ", info$num_channels, "\n")
#> Number of channels: 2
cat("Number of samples: ", info$num_frames, "\n")
#> Number of samples: 276858
cat("Sampling rate: ", info$sample_rate, "\n")
#> Sampling rate: 44100To read in the file, we call torchaudio_load().
torchaudio_load() itself delegates to the default
(alternatively, the user-requested) backend to read in the file.
The default backend is av, a fast and
light-weight wrapper for Ffmpeg. As of
this writing, an alternative is tuneR; it may be requested
via the option torchaudio.loader. (Note though that with
tuneR, only wav and mp3 file
extensions are supported.)
wav <- torchaudio_load(soundfile)
dim(wav)
#> [1] 2 276858For torchaudio to be able to process the sound object,
we need to convert it to a tensor. This is achieved by means of a call
to transform_to_tensor(), resulting in a list of two
tensors: one containing the actual amplitude values, the other, the
sampling rate.
waveform_and_sample_rate <- transform_to_tensor(wav)
waveform <- waveform_and_sample_rate[[1]]
sample_rate <- waveform_and_sample_rate[[2]]
paste("Shape of waveform: ", paste(dim(waveform), collapse = " "))
#> [1] "Shape of waveform: 2 276858"
paste("Sample rate of waveform: ", sample_rate)
#> [1] "Sample rate of waveform: 44100"
plot(waveform[1], col = "royalblue", type = "l")
lines(waveform[2], col = "orange")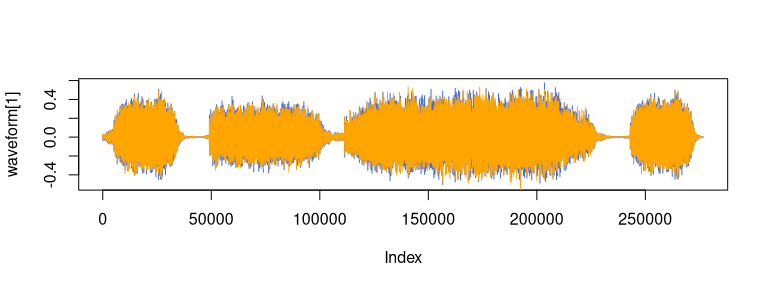
Finally, let’s create a spectrogam!
specgram <- transform_spectrogram()(waveform)
paste("Shape of spectrogram: ", paste(dim(specgram), collapse = " "))
#> [1] "Shape of spectrogram: 2 201 1385"
specgram_as_array <- as.array(specgram$log2()[1]$t())
image(specgram_as_array[,ncol(specgram_as_array):1], col = viridis::viridis(n = 257, option = "magma"))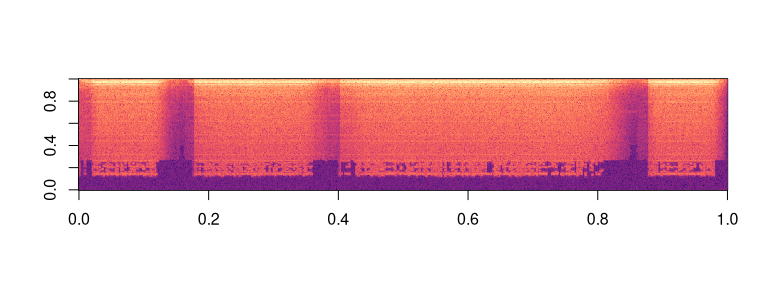
Please note that the torchaudio project is released with
a Contributor
Code of Conduct. By contributing to this project, you agree to abide
by its terms.