|
|
|
| Bu makalenin farklı dillerde bulunduğu adresler: English Deutsch Francais Turkce |
![[Photo of the Author]](../../common/images2/iznoT2.png)
Iznogood <iznogood/at/iznogood-factory.org> Yazar hakkında: Bir süreliğine GNU/Linux ile ilgilendim ve şu anda Debian sistemi kullanıyorum. Elektronik çalışmalara rağmen; çoğunlukla, GNU/Linux topluluğu için, bir Fransızca çeviri çalışması yapıyorum. Türkçe'ye çeviri: ONUR YILMAZ <onur2029(at)yahoo.com> İçerik: |
Kâğıttan HTML 'e dönüşüm için bir araç zinciriÖzet:
Burada, bir geleneksel kâğıt dergiyi HTML 'e çevirmek için kullanılan bir araç zinciri anlatılmaktadır.
Taramadan html biçimine kadar olan süreci açıklayacağım.
|
Bazı US üniversitelerinin Google 'a, kütüphanelerini dijitalleştirmek
(sayısal ortama aktarmak) için, yardım edeceğini veya izin vereceğini
okudum. Ben Google değilim ve bir üniversite kütüphanem yok; fakat
elektronik hakkında bazı eski kâğıt dergilerim var. Ve kâğıt kalitesi iyi değil:
Sayfalar işe yaramaz hale gelmeye başladı, grileşti...
Daha sonra dijitalleştirmeye
karar verdim; çünkü konular yaklaşık olarak 10 yıl önce kapanmasına rağmen, bazı makaleler
daima güncel!
Başlamak için, veriyi bilgisayara aktarmak gerekli. Bir tarayıcı bana bunu
yapmama izin verir: bazı uyumluluk denetimlerinden sonra bir tarayıcı aldım, kullanılmış
fakat ucuz ScanJet 4300C. Ve biraz internet gezintisiyle, onu yapılandırmak için
gerekli ayarları buldum.
Debian 'da, sane, xsane, gocr ve gtk-ocr 'ı olağan şekliyle kurdum:
apt-get install sane xsane gocr gtk-ocrroot iken.
sane-find-scannersonra bazı dosyaları düzenlemek için /etc/sane.d/ 'e gittim:
hp niashve diğer her şeyi yorum konumundan çıkarttım (satır başlarındaki # 'leri kaldırarak).
/dev/usb/scanner0 option connect-deviceve diğer her şeyi yorum konumundan çıkarttım.
chgrp scanner scanner0ve tarayıcıyı root olmadan kullanabilmek için kullanıcı olarak iznogood 'u ekledim:
adduser iznogood scannerBir yeniden başlatma ve tamamlandı!
append="hdb=ide-scsi ignore hdb"sonra
liloişleme sokulması amacıyla.
/dev/sdc0 /dvdrom iso9660 user, noauto 0 0Sonra scd0 gurubunu cdrom 'a değiştirdim
chgrp cdrom scd0Oldukça kolay.
İşleme devam etmek için, bazı yazılımlara gereksinimim vardı:
sane, xsane, gimp, gocr, gtk-ocr, bir metin editörü, bir html editörü ve biraz disk alanı.
Sane tarayıcı arka ucu (arka plan işlerini yapan program veya program parçası) ve
xsane grafiksel ön uç (kullanıcı arabiriminden sorumlu olan program veya program parçası).
Amacım çözünürlüğü maksimum tutmak ve her sayfa için 50 MB bir dosya elde etmek,
üzerinde çalışmak için bir sabitdiskte depolamak ve tamamlandığı zaman, bir DVD-ROM
üzerine saklamaktı.
Çözünürlüğü 600 dpi 'a getirdim, biraz daha parlaklık verdim ve dönüştürmeye başladım.
Çok eski bir bilgisayar olduğundan (bir PII 350 MHz), biraz zaman aldı fakat
iyi ve doğru bir görüntüye sahip oldum. Onu png biçiminde sakladım.
Neden böyle bir çözünürlük ve 50 MB dosya? Arşiv ve ilerideki sayısal işleme
için çözünürlüğü maksimum tutmak istedim.
Gimp kullanarak sayfayı grafiksel görüntülere ve sadece taranmış metin içeren
görüntülere kestim.
Grafikler, html sayfasına uyacak şekilde küçültülmüş boyutlarla, png olarak saklandı
ve metin görüntüleri küçültülmedi, ama renkliden gri ve tonlarına dönüştürüldü (Tools, Colors Tools,
Threshold ve Ok) ve optik tanıma yazılımıyla işlemek için .pcx uzantısıyla saklandı.
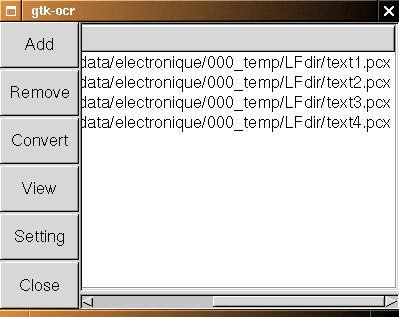
cat *.txt > test.txtbir test.txt 'te sahip oldum ve bir metin editörüyle bazı ayarlamalar yapmam gerekti. (fransızca olmayan karakterler kaldırıldı, sözcükler düzeltildi...).
Gençliğimde bana bu atasözünü söyleyen, bir matematik öğretmenini daima
hatırlarım:
"Tembel olmak için, zeki olman gerekir".
Tamam, tembel olmaya başladım !!!! ;-)
Kolaylıkla otomatikleştirilmeyen bazı el yordamı gerektiren bölümler var (dizin yaratılması,
tarama, gimp 'te kesme biçme ve dosya yaratılması). Geri kalanını otomatikleştirebilirsiniz.
Bash betikleme hakkında inanılmaz bir İngilizce öğretici var, ABS (Advanced Bash Scripting Guide)
(İleri Bash Betikleme Kılavuzu), ve bir Fransızca çevirisini buldum.
İngilizce versiyonunu www.tldp.org 'da bulabilirsiniz.
Bu kılavuz küçük bir program yazmama izin verdi. İşte betik:
#!/bin/bash REPERTOIRE=$(pwd) cd $REPERTOIRE mkdir ../ima mv *.png ../ima/ for i in `ls *` do gocr -f UTF8 -i $i -o $i.txt done cd .. mv ima/ $REPERTOIRE cd $REPERTOIRE cat *.txt | sed -e 's/_//g' -e 's/(PICTURE)//g' -e 's/ì/i/g' \ -e 's/í/i/g' -e 's/F/r/g' -e 's/î/i/g' > test.txt
ocr-rppwd betiğe dizin yolunu verecek, sonra dizinin dışına ima yaratılır ve tüm .png dosyaları içine taşınır. Tüm .txt dosyaları sonra listelenir, gocr ile işlemden geçirilir, test.txt 'de birleştirilir ve Fransızca karakterleri uydurmak için bazı değişiklikler yapılır.
|
|
Görselyöre sayfalarının bakımı, LinuxFocus Editörleri tarafından yapılmaktadır
© Iznogood, FDL LinuxFocus.org |
Çeviri bilgisi:
|
2005-08-25, generated by lfparser version 2.46